[논문리뷰] ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR ‘21 Oral)
1. Introduction
- Self-attention 구조를 적용한 Transformer가 NLP task에서 크게 성공한 것에 영향을 받아, Vision task에도 self-attention 구조를 적용하려는 시도가 있었다. 하지만 기존의 Conv 구조에 비해 낮은 성능을 기록했다.
- 이에 저자들은 image를 여러 개의 patch로 나눈 다음, 각각의 patch에 대한 linear projection 결과를 Transformer의 token처럼 기능하게 하는 Vision Trasnformer (ViT) 모델을 제안한다.
- ViT를 ImageNet과 같은 mid-sized dataset으로 학습하면 비슷한 크기의 ResNet 모델에 비해 낮은 성능을 기록했는데, 저자들은 그 이유가
Transformer의 경우 CNN에 비해 낮은 inductive bias를 가지기 때문에 충분하지 않은 data로 학습하면 일반화 성능이 떨어진다고 한다. - 하지만 그보다 큰 ImageNet-21k, JFT-300M과 같은 dataset으로 학습하면 ViT가 CNN의 성능을 넘어설 수 있음을 보였다.
2. Related work
- Image의 각 pixel에 대해 self-attention을 그대로 적용하는 것은 quadratic cost로 인해 현실적으로 불가능하기에, 이를 근사화하기 위해 self-attention의 범위를 제한하는 식으로 접근했다. 하지만 이러한 specialized attention 구조는 H/W 가속기에서의 연산을 위한 추가 작업이 필요하다는 단점이 있다.
ViT와 가장 유사한 연구로, image로부터 2x2 patch를 추출한 다음 self-attention을 적용했던
Cordonnier et al. (2020)이 있다. ViT의 novelty는 다음과 같다.- 큰 규모의 dataset으로 pre-train함으로써 CNN 구조의 SOTA 성능을 뛰어넘을 수 있었다.
- 2x2 보다 큰 patch size 덕분에 더 큰 이미지에도 적용 가능하다.
또 다른 유사한 연구로는 transformer를 적용하여 unsupervised 방식으로 pixel을 예측하도록 학습했던 image GPT (iGPT)
Chen et al. (2020a)가 있다.- Image의 resolution과 color space를 제한했다는 단점이 있다.
- ImageNet-21k, JFT-300M과 같이 큰 dataset에 대한 CNN의 transfer learning에 대한 연구도 있다.
3. Method
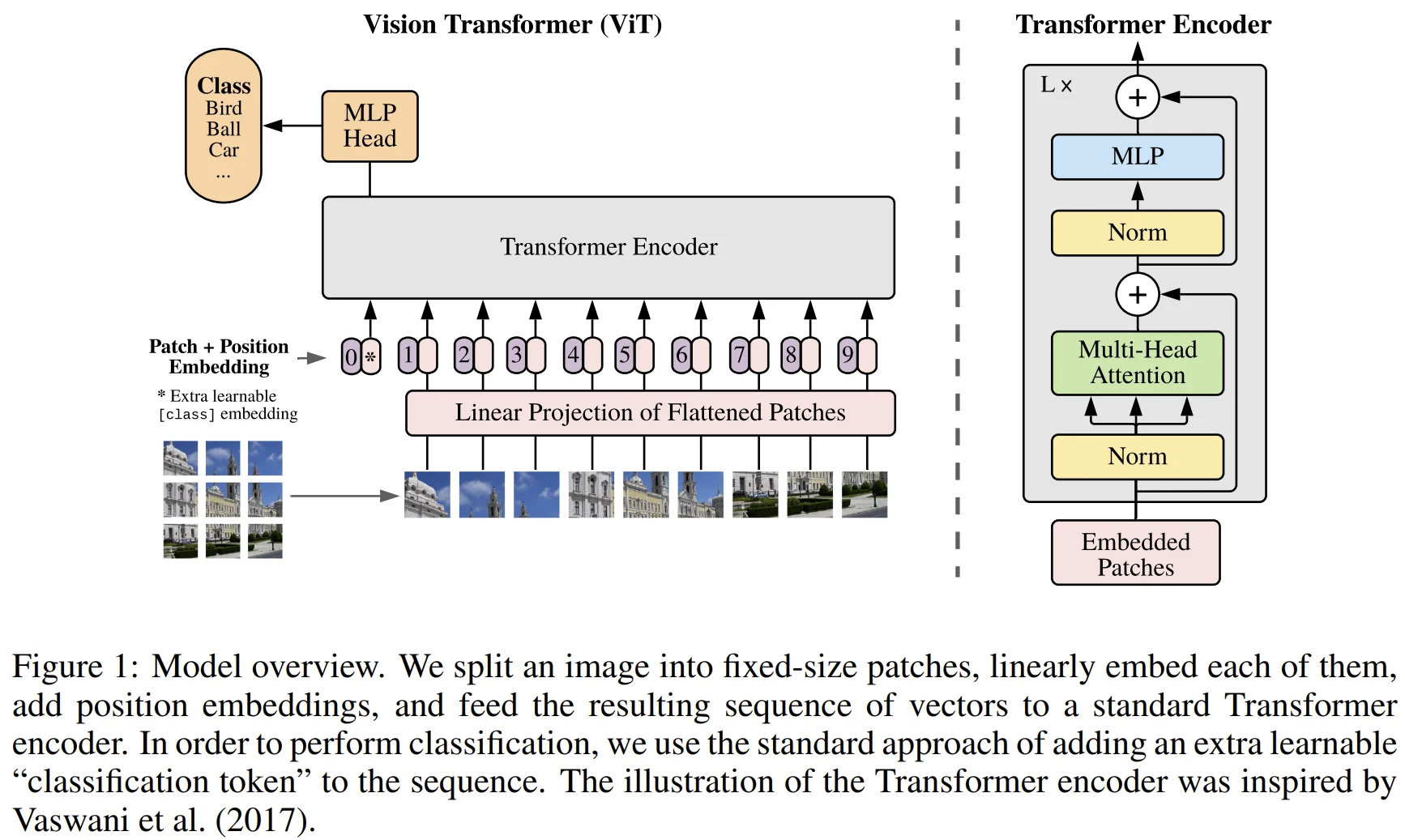
- 저자들은 NLP Transformer 구조의 확장성과 효율성을 강조하기 위해, 거의 수정하지 않았다고 한다.
3.1 Vision Trasnformer (ViT)
Patch embeddings
- 2D image를 여러 개의 patch로 나누고, 이를 sequence of flattened 2D patches로 만든다. 이후 $P^2 * C$ size를 고정된 size $D$로 linear projection한다.
- $H * W$ size의 image를 $P * P$ size의 patch로 나누는 과정에서 flatten이라는 용어를 사용한 것으로 보인다. (아래의 vit-pytorch 코드를 통해 직관적으로 이해할 수 있다.)
# https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
Class embedding
- BERT의 class token과 유사하게, 학습이 가능한 class embedding을 추가한다.
- Classificiation head는 pre-train에서 1개의 hidden layer를 가진 MLP를 사용하고, fine-tune에서는 하나의 linear layer만 사용한다.
Position embeddings
Patch embeddings에 class embedding을 concat한 다음에, position embeddings를 통해 위치 정보를 주입한다.
Appendix D.4
- Positional embedding을 사용하지 않았을 때와 비교하여 성능 향상이 크게 있었다. 반면, positional embedding이 어떤 방식인지는 중요하지 않았다. (Ex. 1D, 2D, Realtive positional embedding)
- 이에 대해, 저자들은 ViT encoder가 pixel-level이 아닌 patch-level에서 동작하기 때문으로 생각한다. (224x224 size가 아닌 14x14 size)
Inductive bias
- CNN은 locality, 2D neighborhood 구조, translation equivariance가 각 layer마다 적용되어진다.
- 반면, ViT는 MLP layer만 locality, translation equivariance 성질을 가진다. 그리고 self-attention layer는 global하게 적용되며, 2D neighborhood 구조는 image를 patch로 나눌 때와 fine-tune 단계에서 다양한 크기의 image에 positional embedding을 적용할 때에만 적용된다. 또한, positional embedding은 patches 사이의 2D 정보를 갖고 있지 않기 때문에 이러한 위치 정보는 scratch부터 학습되어야 한다.
Hybrid architecture
- 본 논문의 hybrid model은 image 대신 CNN feature map을 나눈 patch에 embedding projection을 적용한다.
3.2 Fine-tuning and higher resolution
- Large dataset에 대한 pre-train 이후, downstream task로의 fine-tune 방식으로 학습했다.
- 또한, fine-tune 단계에서 image size를 키우는 것은 종종 사용되는 기법인데, 이를 적용하기 위해 저자들은 patch의 크기를 고정했고 그에 따라 patch의 개수가 많아지게 된다.
- ViT는 임의의 sequence length도 처리할 수 있긴 하지만, sequence length가 바뀌면 당연히 pre-trained position embeddings을 사용할 수 없게 된다. 이를 해결하고자 origin image에서의 위치를 반영한 2D 보간법을 적용했다. 이러한 resolution adjustment, patch extraction 과정이 유일하게 ViT에 의도적으로 주입된 image의 2D 구조에 대한 inductive bias이다.
4. Experiments
4.1 Setup
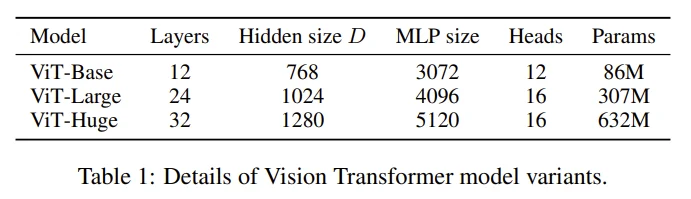
Model variants
- ViT : ViT-B, ViT-L, ViT-H (ViT-L/16에서 뒤에 붙은 16은 patch size를 의미함)
- Big Transfer (BiT) : supervised transfer learning으로 학습한 large ResNet 모델
- Hybrid : 중간의 feature map을 size 1의 patch로 나누어 ViT의 input으로 함
Training & Fine-tuning
Pre-training
- Adam : ResNet 계열은 보통 SGD를 사용해왔지만, 저자들의 경우에는 Adam으로 pre-train했을 때 SGD보다 성능이 더 좋다고 한다.
Fine-tuning
- SGD with momentum
Metrics
- Fine-tuning accuracy : 각각의 dataset에 대한 fine-tuning 후의 accuracy 측정
Few-shot accuracy : 아래 논문을 참고하여 각 class에 대한 logit이 {-1, 1}로 regularized된 least-squares regression 문제로 접근하여 accuracy 측정
- Fine-tuning accuracy를 구하는 비용이 너무 큰 경우만, few-shot accuracy를 구했다고 한다.
- 참고 논문 : Evaluation of Neural Architectures Trained with Square Loss vs Cross-Entropy in Classification Tasks
4.2 Comparison to state of the art
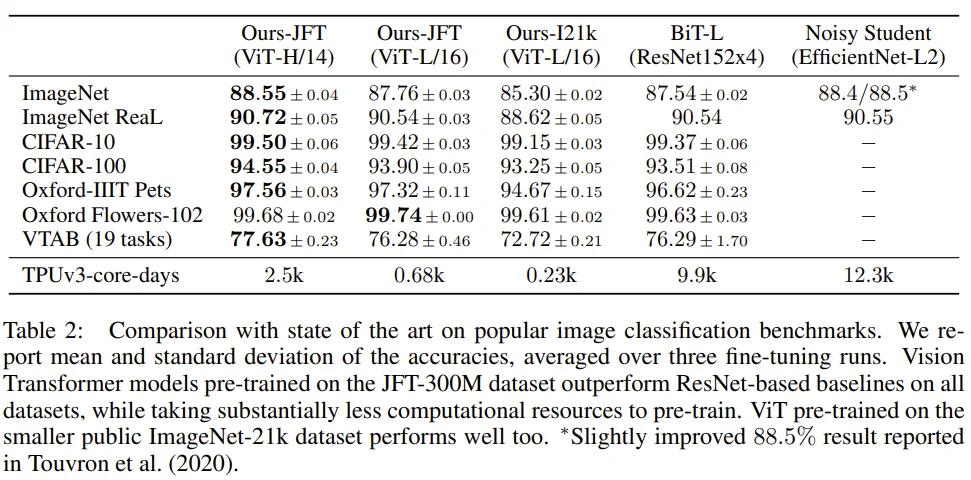
- ViT 모델 간 성능을 비교할 때, ImageNet21k 보다 JFT-300M의 성능이 좋으며 ViT-L/16 보다 ViT-H/14 성능이 좋다.
- BiT, Noisy student와 비교할 때, JFT-300M으로 학습한 ViT-H/14가 가장 성능이 좋으며 학습시간도 굉장히 짧다.
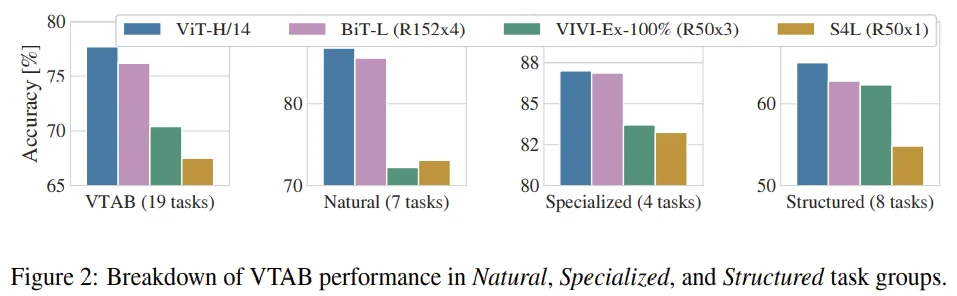
- VTAB 성능 면에서도 BiT-L보다 성능이 좋다.
4.3 Pre-training data requirements
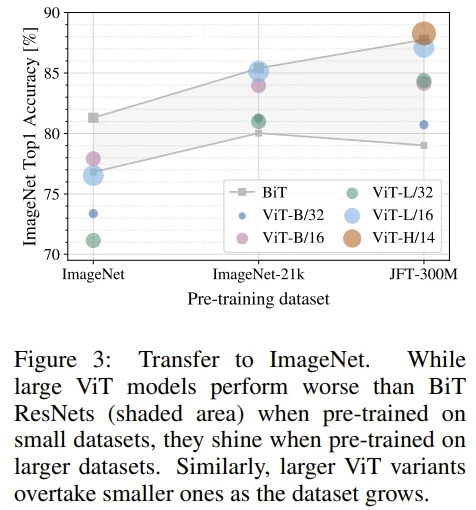
- ImageNet에서는 BiT가 더 성능이 좋았지만, JFT-300M에서 ViT가 더 성능이 잘 나온다.
- 또한, JFT-300M에서 ViT 모델의 크기와 성능이 비례하는 모습이 나타난다.
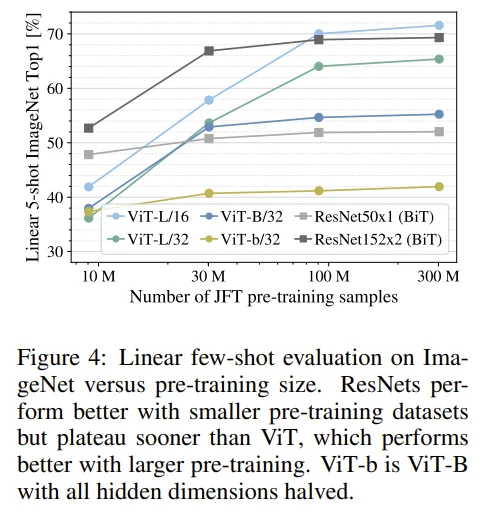
- Pre-train시 JFT-300M dataset 중 일부만을 사용하여 dataset 크기에 따른 성능 변화를 확인했다. early-stopping을 적용했고, full fine-tuning 대신 few-shot linear acc를 구했다.
- 10M 정도에서는 BiT가 우세한 모습을 보이지만, 점차 dataset size가 커지면서 ViT의 성능이 꾸준히 오르는 것을 볼 수 있다.
4.4 Scaling study
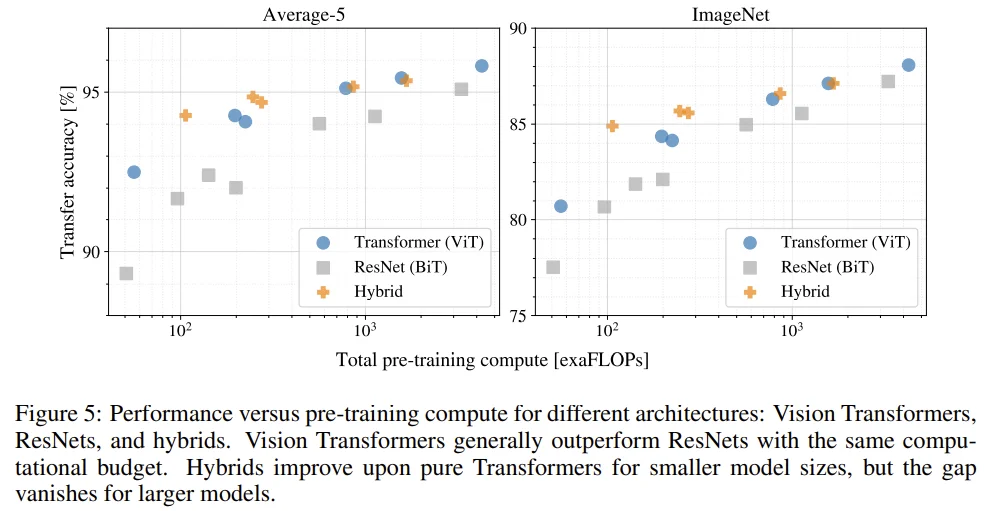
- ViT는 performance/compute trade-off에서 ResNet보다 좋다.
- 작은 size에서 Hybrid 모델이 ViT를 이기는 모습이 관찰되었다.
가장 큰 ViT-H/14의 경우도 아직 포화되었다는 징후가 보이지 않는다. -> 더 키워볼 만 하다.
Appendix D.5
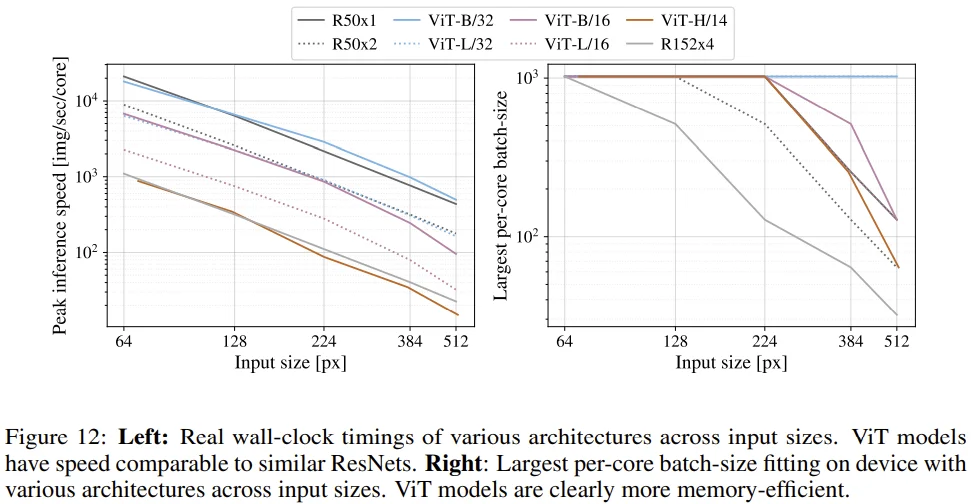
Left
- Input size 대비 추론 속도를 나타낸 그래프로, ViT가 이론적으로 bi-quadratic cost를 갖고 있기 때문에 input size가 커짐에 따라 미묘하게 추론 속도가 빨라지는 것을 볼 수 있다.
Right
- Input size 대비 largest batch size를 나타낸 그래프로, ResNet 모델에 비해 ViT 모델이 효율적인 memory로 동작한다는 점을 확인할 수 있다.
4.5 Inspecting vision transformer

Left
- 학습된 embedding filter의 주성분을 시각화한 것으로, CNN filter와 유사하게 representation이 가능한 것처럼 보인다.
Center
position embedding 사이의 유사도를 구한 것으로, 가까운 거리일수록, 가까운 row/column일수록 유사도가 높은 것을 볼 수 있다.
- 저자들은 Appendix D.4 에서 다루었던, 2D-aware embedding이 효과가 없는 것처럼 보였던 이유가
이미 1D embedding으로도 2D image를 잘 represent했기 때문으로 생각된다고 했다.
- 저자들은 Appendix D.4 에서 다루었던, 2D-aware embedding이 효과가 없는 것처럼 보였던 이유가
Right
Attention distance란, attention weight에 기반하여 각 정보가 어떤 정보와 integrated되어 있는지를 나타낸 값으로, CNN의 receptive field와 유사한 개념이라고 한다.
Network depth가 깊어질수록 attention distance가 증가하는 것을 볼 수 있다. 즉, ViT는 network가 깊어짐에 따라 image region에 대한 attention이 잘 되고 있으며, 이를 바탕으로 classification을 수행할 수 있다.
Attention D.7
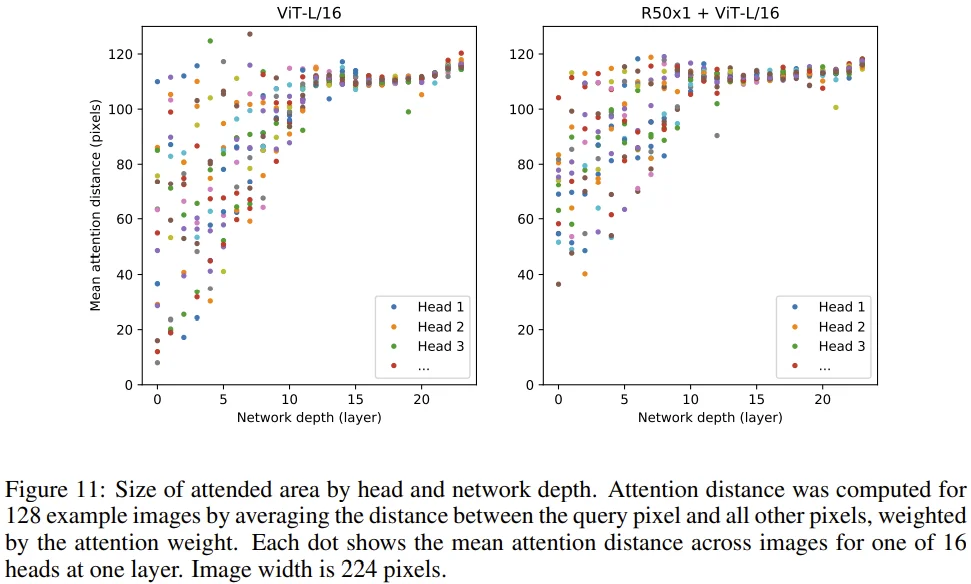
- Network depth가 0인 경우를 보자. ViT 모델에 비해 ResNet 모델은 약 2배의 mean attention distance를 보인다. 이는 앞서 설명했던 image에 대한 CNN 구조의 inductive bias가 갖는 장점으로 볼 수도 있다.
4.6 Self-supervision
- Transformer의 성공은 훌륭한 scalability 뿐만 아니라 대규모의 self-supervised pre-training 덕분이라고 보는 연구가 있다. 이에, BERT에서 사용된 mask 개념을 차용하여 masked patch predicition을 통해 ViT의 self-supervision을 실험했다.
- ViT-B/16 모델에 적용했을 떄, scratch보다는 2% 높은 성능을 보였지만 supervised pre-training보다는 4% 낮은 성능을 기록했다.
5. Conclusion
We have explored the direct application of Transformers to image recognition. Unlike prior works using self-attention in computer vision, we do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, we interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP. This simple, yet scalable, strategy works surprisingly well when coupled with pre-training on large datasets. Thus, Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train.
Challenges
Apply ViT to other computer vision tasks (detection, segmentation)
Self-supervised pre-training method (4.6)
Futher scailing of ViT
Reference
https://github.com/lucidrains/vit-pytorch