[논문리뷰] MLP-Mixer: An all-MLP Architecture for Vision (NIPS ‘21)
ViT 논문 - Mixer 논문 - Mixer Open Review 순으로 읽으시기를 추천드립니다.
1. Introduction
Computer vision 분야에서 CNN 모델이 기본이 되어왔지만, 최근 attention을 기반으로 한 ViT가 SOTA 성능에 도달할 수 있었습니다. 이러한 상황에서 저자들은 MLP-Mixer(Mixer)라는 간단한 컨셉의 모델을 제안합니다. Mixer의 특이한 점은 convolution과 self-attention을 사용하지 않고 MLP layer만으로 구성되어 있다는 점입니다.
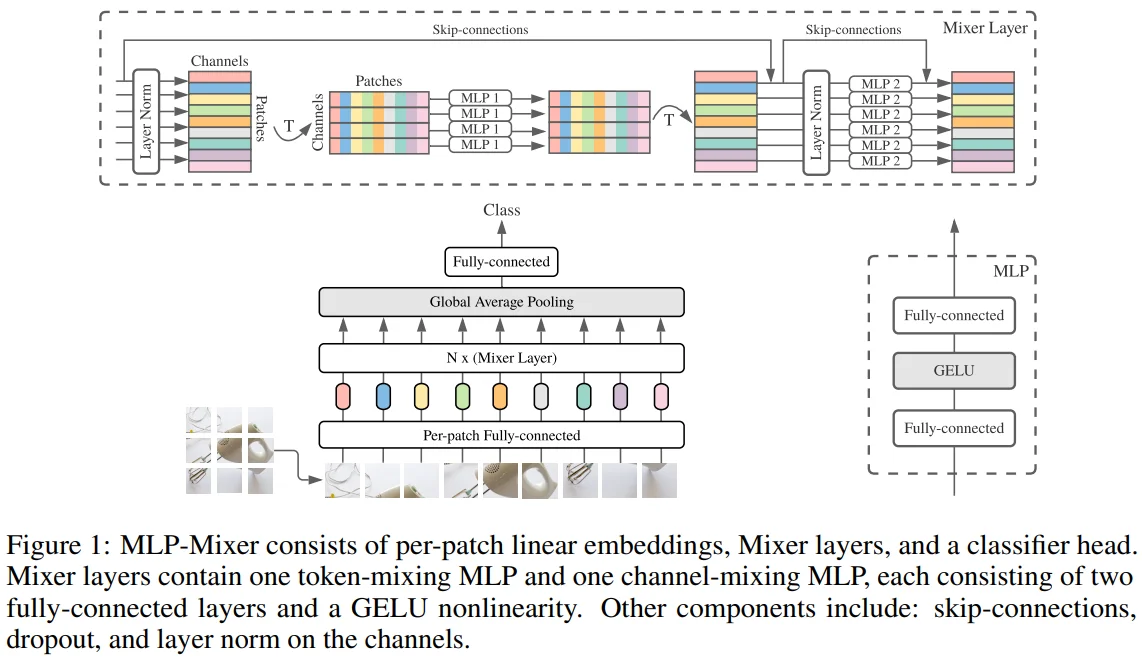
Figure 1을 보면 MLP-Mixer는 크게 2종류의 MLP layer로 구성됩니다.
MLP 1 = Token-mixing MLP : 다른 token과 spatial 정보를 주고 받으며, 각 channel에 독립적으로 작용
MLP 2 = Channel-mixing MLP : 다른 channel과 정보를 주고 받으며, 각 token에 독립적으로 작용
이러한 MLP 작동 방식은 아래의 매칭을 통해 Mixer를 특별한 형태의 CNN으로 볼 수도 있습니다.
Token mixing MLP : single-channel depth-wise convolution + full receptive field + parameter sharing
Token mixing 과정은 channel axis와 patch(token) axis를 transpose한 이후 MLP를 거치고 다시 원래 형태로 transpose하게 됩니다. 이 과정을 single-channel depth-wise convolution + full receptive field + parameter sharing과 동일하게 볼 수 있다고 했습니다. 그 이유는 다음과 같습니다.
- 각 patch의 single channel이 MLP의 input으로 feed되고 이를 모든 channel에 대해 진행한다는 점에서 single-channel depth-wise convolution과 매칭되고,
- 모든 patch(token)을 사용한다는 점에서 full receptive field를 가진다고 볼 수 있으며,
- 동일한 filter를 사용한다는 점에서 parameter sharing이 필요하게 됩니다.
Channel mixing MLP : 1 x 1 convolution
- Channel mixing 과정은 input과 output의 channel 값이 같기 때문에, 1 x 1 concolution을 통해서도 수행할 수 있습니다.
하지만 저자들이 말하길 convolution layer는 MLP의 일반적인 행렬곱보다 복잡한 연산을 수행하기 때문에 앞선 명제는 성립하지 않게 된다고 합니다.
이처럼 Mixer는 간단한 구조임에도 ~100M 정도 되는 large dataset으로 pre-train할 때, CNN 및 ViT가 도달했던 SOTA에 준하는 성능을 보여줍니다. 반면 ~1M, 10M 정도 되는 중간 규모의 dataset으로 pre-train할 때는 regularization technique이 적용되어야 일정 수준의 성능이 보장되었습니다. 즉, dataset 크기가 작은 경우 ViT와 마찬가지로 CNN 계열보다 낮은 성능을 보였습니다.
2. Mixer Architecture
Computer vision 분야에서 feature를 mix하는 layer는 주어진 공간에서만 mix하거나 (local), 다른 공간의 feature와 mix하는 (global) 방식입니다. 이러한 관점에서 CNN, ViT, Mixer의 architecture를 설명하고 있습니다. (참고로, CNN 모델의 주어진 공간은 feature point 1개를 의미하지만 ViT, Mixer 모델의 주어진 공간은 patch 1개를 의미합니다.)
CNN (Convolution) : feature 단위
N x N convolution (N>1) and Pooling : global
1 x 1 convolution : local
ViT (Attention) : patch 단위
Self-attention layer : local + global
MLP-block : local
Mixer : patch 단위
Channel mixing : local
Token mixing : global
이어서, Mixer의 특징을 소개하고 있습니다.
Per-patch Fully-connected layer (Figure 1) : 모든 patch는 동일한 projection matrix로 linear project 됩니다.
- ViT와 다르게, Mixer는 position embedding을 사용하지 않습니다. 그 이유는 token-mixing MLP가 input token의 순서에 영향을 받기 때문에, position embedding 없이도 token의 위치 정보를 학습할 수 있기 때문입니다.
ViT는 self-attention layer로 인해 input patch 수에 quadratic하게 cost가 증가하는 반면, Mixer는 input patch 수에 linear하게 cost가 증가합니다. 이는 아래의 Table3에서도 확인할 수 있습니다.
- 초기 embedding layer인 per-patch fully-connected layer를 제외하면, 모든 layer는 input과 ouput이 같은 크기입니다. (isotropic)
- Mixer는 MLP 외에도 skip connection, layer nomalization을 사용하며, class 예측에는 GAP layer와 classification head를 사용합니다.
다음으로, mixing MLP에 대한 자세한 설명이 언급되고 있습니다.
Channel mixing MLP를 통해 CNN의 주요 특징 중 하나인 positional invariance 성질을 주입할 수 있습니다.
- Positional invariance는 직역하면 위치에 따른 변화가 없다는 뜻입니다. 이것이 왜 CNN의 주요 특징인지를 간략히 설명하면, 기본적으로 convolution layer는 위치에 따라 값이 변하기 때문에 positional equivariance 성질이 있지만, convolution layer가 sliding하며 공유되는 parameter를 update하기 때문에 positional invariance 성질도 갖게 되기 때문입니다.
Token mixing MLP 처럼 parameter sharing을 하는 것이 일반적인 방법은 아닙니다. 이와 비슷한 경우로 separable convolution이 있는데, 이는 각각의 channel에 대해 독립적으로 convolution을 진행한다는 점에서 Mixer와 유사하지만, Mixer는 kernel을 공유한다는 점에서 차이가 있습니다.
- 이처럼 parameter를 묶는 것은 hidden dimension, sequence length가 커질 때 학습 속도가 너무 빨라지지 않도록 억제할 수 있고, memory 관점에서 유리하며, 저자들이 말하길 parameter sharing을 하지 않고 각기 다른 MLP를 사용했을 때와 비교하여 metric score에 큰 차이는 없었다고 밝혔습니다.
3. Experiments
Pre-training
- resolution : 224
- Adam with $B_1$ = 0.9, $B_2$ = 0.999
- batch size : 4096
- linear learning rate warmup of 10k steps and linear decay
- weight decay
- gradient clipping at global norm 1
data augmentation
JFT-300M
- crop (Going Deeper with Convolutions 논문)
- random horizontal flip
ImageNet, ImageNet-21k
- RandAugment
- mixup
- dropout
- stochastic depth (Deep Networks with Stochastic Depth 논문)
Fine-tuning
resolution
- 224 : same with pre-train
- higher resolution (448) : patch resolution fixed + increase the number of patches
- SGD
- batch size : 512
- cosine learning rate schedule with a linear warmup
- not use weight decay
- gradient clipping at global norm 1
Metrics
computational cost
- total pre-training time on TPU-v3 (ex. FLOPs)
- throughput in images/sec/core on TPU-v3
quality
- top-1 downstream accuracy after fine-tuning
- few-shot accuracies
4. Models
- MLP-based Mixer (pink)
convolution-based models (yellow)
- Big Transfer (BiT) : ResNets optimized for transfer learning
- NFNet : normalizer-free ResNets
- MPL : EfficientNet architecture, pre-trained on JFT-300M using meta-pseudo labelling from ImageNet
- ALIGN : EfficientNet architecture, pre-trained on noisy web image text pairs in a contrastive way
attention-based models (blue)
- HaloNet : use a ResNet-like structure with local self-attention layers instead of 3 x 3 convolutions
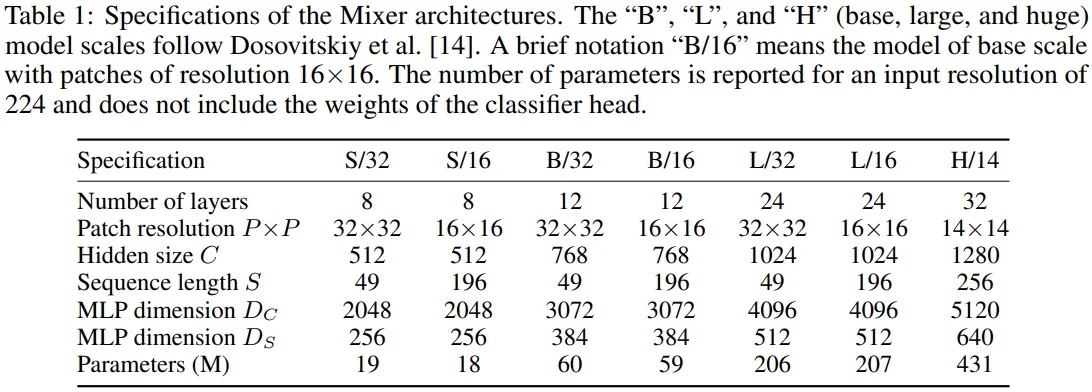
[Table 1 설명]
- 실험에 사용된 Mixer 모델을 정리한 표입니다.
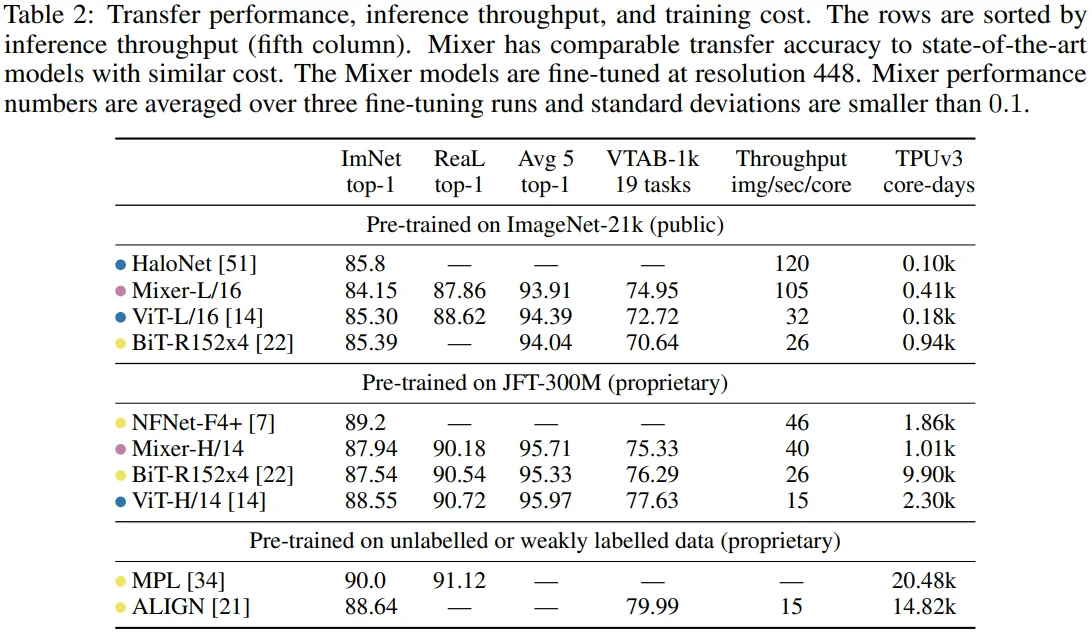
[Table 2 설명]
- Pre-train dataset size가 커지면(ImageNet-21k -> JFT-300M) Mixer의 성능이 유의미하게 향상되는 것을 볼 수 있습니다. (84.15 -> 87.94)
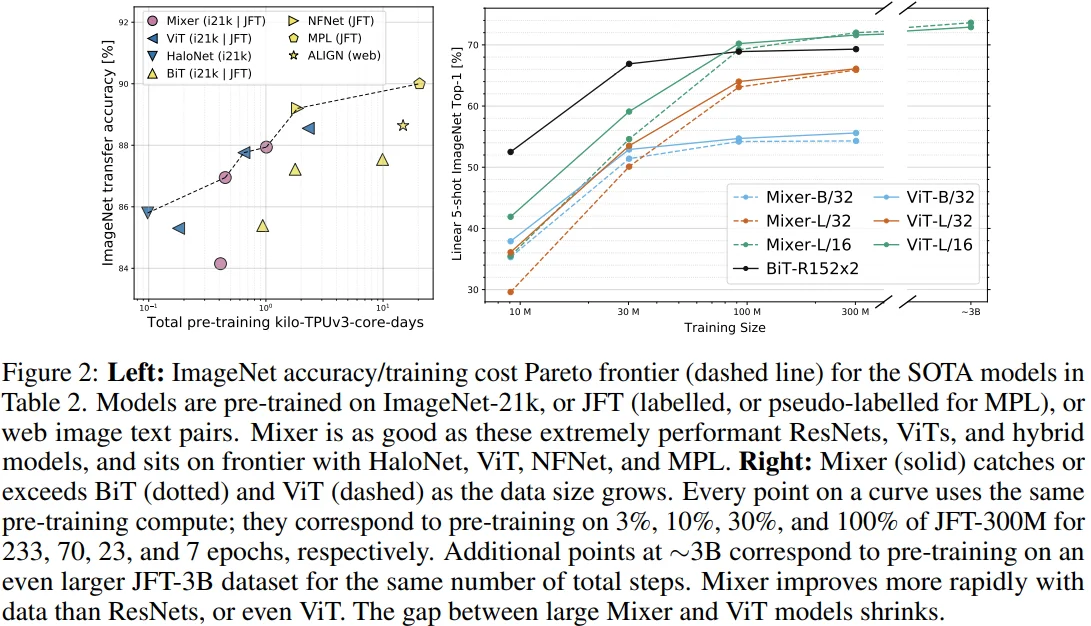
[Figure 2 설명]
Left : 전반적으로 Mixer는 accuracy-cost trade-off 관계에서 다른 모델과 비교하여 경쟁력이 있다고 주장합니다.
Right : dataset size가 커질수록 Mixer가 유의미한 성능 향상을 보이고 있습니다.
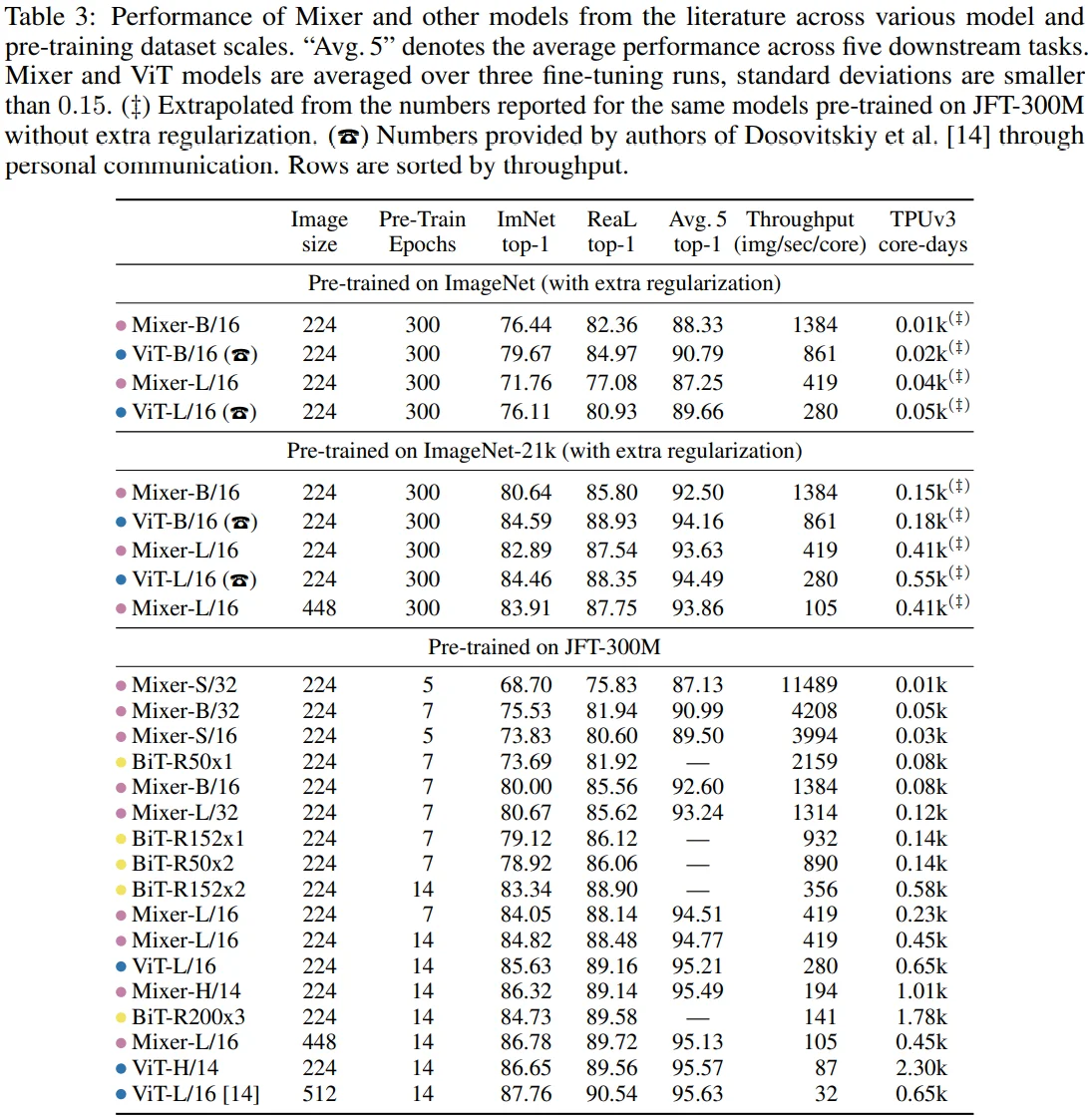
[Table 3 설명]
- ImageNet-1k로 pre-train할 경우, Mixer-B/16(acc 76.44), ViT-B/16(79.67)로 성능 차이가 꽤 있는데, 두 모델의 loss value는 큰 차이가 없었다고 합니다. 이를 근거로 저자들은
Mixer-B/16 모델이 overfitting되기 쉽다고 판단하였으며, 이러한 경향은 Mixer-L/16(71.76), ViT-L/16(76.11)에서도 확인할 수 있습니다. - 반면, JFT-300M으로 pre-train할 경우, Mixer-H/14(86.32), ViT-H/14(86.65)로 성능 차이가 0.3 정도만 존재하는데, training-time은 Mixer-H/14이 약 2.3배 빠른 결과를 보여줍니다.
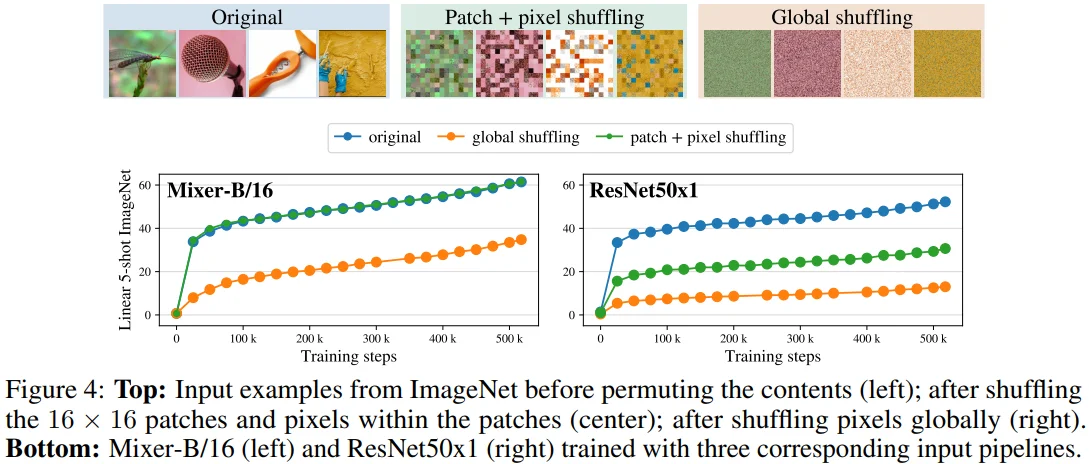
[Figure 4 설명]
- Patch + pixel shiuffling : Mixer 동작 방식과 동일하게 image를 patch로 분할한 다음, patch 순서를 shuffle하고, patch 내 pixel도 shuffle합니다.
- Global shuffling : 무작위로 pixel을 shuffle합니다.
- CNN 계열의 ResNet 모델은 당연히 shuffle된 image에서 성능이 좋지 않았습니다. 반면, Mixer는 original과 비교해서 patch + pixel shuffling의 성능이 비슷했습니다. 즉, Mixer는 patch의 순서나, 1개의 patch 내에 있는 pixel의 순서와 무관한 성능을 보여줍니다.

[Figure 5 설명]
- Figure 5는 token mixing MLP 처음 3개의 hidden units을 시각화한 그림입니다. 3개의 그림은 각각 8 x 8 크기의 그림으로 구성되는데, 이는 전체 384개 (Mixer-B/16의 MLP dimension $D_S$) 중 filter frequency를 기준으로 (아마도 간단한 형태 순으로) sort하여 64개를 plot한 결과입니다.
- 또한, 그림들을 잘 보면 비슷한 형태가 2개 연이어 등장합니다. 이는 CReLU를 제안했던 Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units 논문에 등장하는 개념으로, CNN의 초기 convolution layer에 존재하는 어떤 filter와 부호가 반대이면서 비슷한 형태의 filter가 존재한다는 내용을 반영한 것으로 보입니다.
Figure 5를 통해 저자들이 전달하고자 했던 메시지는 2가지로 보입니다.
- Convolution layer의 weight를 시각화할 때 등장하는 Gabor filter와 같은 형태가 보이지 않습니다.
- Token mixing MLP의 layer가 깊어질수록, global 영역과의 상호 작용을 통해 그 형태가 복잡해지는 것을 볼 수 있습니다.

[Figure 7 설명]
- Linear embedding layer를 시각화할 때, patch size가 32인 경우 Gabor-filter와 같은 형태를 볼 수 있었고 16인 경우 그보다 불분명한 형태를 확인할 수 있습니다.