[논문리뷰] MAE: Masked Autoencoders Are Scalable Vision Learners (CVPR ‘22 Oral)
- 이번에 리뷰할 논문은 MAE로 알려진 Masked Autoencoder 입니다.
- Facebook (Meta)의 Kaiming He 님이 1저자로 참여했고, CVPR 2022에 accept된 논문이구요.
- Masked image modeling을 처음 제시한 BEiT나, 비슷한 시기에 나온 SimMIM 대비 인용 수도 높고 후속 논문들이 많이 나오는 것 같아 선정하게 되었습니다.
- 전체적으로 vision과 NLP 도메인의 차이에 대한 생각들이 참신하게 느껴졌고, contrastive learning과 관련한 insight도 흥미롭게 읽은 논문입니다.
✔️ Related Work
Autoencoding
Autoencoding은 encoder와 decoder로 이루어졌으며, representation을 학습하는 방법 중 하나입니다. Encoder는 input을 latent representation으로 mapping하고, decoder는 latent를 다시 input으로 reconstruction하는 역할을 수행합니다. 즉, input을 encoder로 압축하고, decoder로 복원하는 구조입니다.
Denoising autoencoders (DAE) 는 autoencoder의 일종으로, input signal에 corruption(=noise)을 가하고 이를 다시 uncorrupted input signal로 복원하는 모델입니다. 저자들이 말하길 MAE는 DAE의 general form으로 볼 수 있다고 합니다.
Masked language modeling (MLM)
NLP 도메인에서 큰 성공을 거둔 pre-training method인 BERT가 MLM에 해당합니다.
Masked image encoding
선행 연구로는 DAE, Context Encoder 등이 있었습니다. 최근에는 NLP 도메인에서 성공했던 BERT에 영감을 받은 iGPT, ViT, BEiT와 같은 연구들이 발표되었습니다.
Self-supervised learning
Self-supervised learning이란 사람이 정의한 supervision 없이 데이터만으로 학습하는 방식입니다. 간단히 말하면, label 없이 학습한다는 의미인데요. 최근 vision 도메인에서는 pre-training objective에 따라 contrastive learning과 masked image modeling (=masked image encoding) 2가지 방식으로 발전하고 있습니다.
전자인 contrastive learning은 NPID에서 시작되었다고 할 수 있고, MoCo, SimCLR, BYOL, SimSiam 등의 연구들이 그 뒤를 이었습니다. Contrastive learning을 한 문장으로 정리하면, siamese 구조의 framework에서 network 1개는 EMA를 통해 다른 network의 weight로 update되고, image augmentation으로 만든 여러 개의 view 중 동일한 이미지에서 나온 view에 대한 similarity를 높이도록 학습하는 방식입니다. 즉, label 없이 학습하기 위해 동일한 이미지에서 나온 것인지를 맞추도록 모델의 pre-training objective를 설정했다고 생각하시면 됩니다.
오늘 리뷰할 MAE는 후자인 masked image modeling에 속하는 방식으로, 이미지의 일부 영역에 masking을 적용하고 다시 원래의 이미지로 복원하는 pre-training objective로 학습하게 됩니다.
✔️ Introduction
NLP 도메인에서 BERT의 성공 이후에도 vision 도메인에서 autoecoding을 활용한 연구 성과가 잘 나오지 않자, 저자들은 vision과 language 도메인의 차이가 어디에서 기인하는 것인지 의구심을 갖게 되었고 다음의 3가지 관점에서 답을 찾았습니다.
Architecture
Vision 도메인에서 CNN 구조는 오랫동안 주류였습니다. 하지만 CNN 구조는 network의 indicator 역할을 수행하는 모듈이 존재하지 않습니다. (Ex. BERT의 mask token, Transformer의 positional embedding) 이러한 architecture gap은 ViT의 등장으로 극복 가능하게 되었습니다.
Information density
언어는 인류가 만들어낸, 의미론적이면서 많은 정보가 축약된 signal입니다. 그렇기에, 문장의 일부 단어를 masking하고 이를 예측하는 pre-training objective로 언어를 학습할 수 있었습니다. (like BERT)
반면 vision 도메인에서 다루는 이미지의 경우, 공간적 중복이 많은 natural signal에 해당합니다. (= 어떤 픽셀의 인접 픽셀은 공간적으로 유사할 확률이 높음) 이를 고려하여 저자들은 매우 높은 비율의 random masking을 적용하게 됩니다. (BERT의 masking 비율은 15% 이지만, MAE의 masking 비율은 75%)
Autoencoder
Autoencoder의 decoder는 latent representation으로부터 input과 동일한 값을 reconstruct하는데, 이는 NLP와 vision 도메인에서 다른 양상을 보이게 됩니다.
NLP 도메인에서는 풍부한 의미 정보를 갖는 단어를 예측하기 때문에 decoder로 단순 MLP도 사용 가능한 반면
(잘못된 해석일 수 있습니다.), 의미 정보가 부족한 pixel을 예측하는 vision 도메인의 decoder는 학습된 latent representation의 의미 수준을 결정하는 데 중요한 역할을 한다고 주장합니다.
위 분석을 바탕으로 저자들은 이미지의 일부를 random masking하고, 이를 다시 pixel level로 복원하는 MAE를 제안합니다.
✔️ Approach
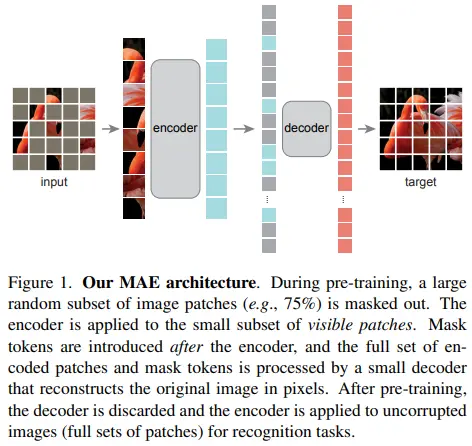
Figure 1을 보면 MAE의 특징들을 쉽게 확인할 수 있습니다. Encoder에 비해 lightweight decoder를 사용하는 asymmetric encoder-decoder design을 갖고 있으며, encoder에서 masked patch를 처리하지 않기 때문에, pre-training time, memory 측면에서 이점이 있고 model scalability가 좋다는 특징이 있습니다. 아래에는 실제 학습에서 이미지가 처리되는 순서대로 자세히 설명하겠습니다.
Masking
MAE는 ViT backbone을 사용하므로 이와 동일한 방식으로 이미지로부터 patch를 얻습니다. 이후 uniform 분포를 따르는 random sampling을 통해 patch에 masking을 적용합니다.
MAE의 masking 비율로 75%라는 높은 값을 적용하여 다음의 2가지 효과를 얻습니다.
공간적 중복이 많은 인접한 patch 정보를 제거함으로써, pre-training objective의 난이도를 어렵게 하여 이미지를 잘 학습합니다. (많이 제거하지 않으면, 너무 쉬워서 학습이 잘 안될 것)
Uniform 분포를 따르는 masking 방식으로 center bias 문제를 방지할 수 있습니다. (예상컨데, contrastive learning에서 view를 만드는데 중요한 역할을 하는 crop augmentation의 경우 이미지의 중심에 편향되는 center bias 문제가 있는데, 이를 고려한 것 같습니다.)
MAE encoder
MAE의 encoder는 recognition을 위한 image representation을 추출합니다.
또한, visible patch만 학습하기 때문에 pre-training cost를 줄일 수 있게 됩니다.
MAE decoder
MAE의 decoder는 pre-training 과정에서만 image reconstruction을 수행하기 때문에, encoder design과 무관한 decoder design이 가능해집니다.
또한, encoder에서 나온 encoded visible token과 mask token을 같이 학습하는데, lightweight decoder를 사용함으로써 pre-training cost를 줄이고자 한 것으로 보입니다. 아래에서 MAE decoder의 forward 과정을 순서대로 확인하실 수 있습니다.
Embed tokens
Encoded visible token의 차원과 decoder의 차원을 맞춰주기 위한 linear projection 입니다.
Append mask token + unshuffle
Unshuffle : masking 구현을 위해 적용했던 shuffle을 되돌리는 과정으로, 이를 위해 encoding에서 적용했던 masking 과정의 index 정보가 필요합니다.
Add positional embedding
앞에서 추가된 mask token은 embedding이 적용되지 않았기 때문에, 추가적인 positional embedding이 필요하게 됩니다.
Apply Transformer blocks
Predictor projection
Loss 계산을 위해 target image와 shape을 맞춰주기 위한 linear projection 입니다.
Output shape = (b, h * w, p**2 * 3) (b=batch_size, h=height, w=width, p=patch_size)
Remove class token
Reconstruction target
MAE의 reconstruction target은 masked patch 영역의 pixel이며, MSE loss를 사용합니다. 그리고 BERT를 따라하여 visible patch에 대한 reconstruction loss를 계산하지 않았습니다.
특이한 점은 loss 계산 전에 target image에 patch 단위의 normalization을 적용했을 때 더 좋은 representation quality를 보였다고 하는데요. 이에 대해 별 다른 이야기는 없지만, transformer block의 layer normalization이 patch 단위로 적용되기 때문인 것으로 생각됩니다.
Simple implementation
MAE는 앞서 언급했던 것처럼, enocder에서 masked patch를 학습하지 않고, lightweight decoder를 사용하기 때문에 효율적으로 학습이 가능한데요. 이뿐만 아니라 encoding의 masking 과정은 단순 random shuffle 이후 visible token만 encoder로 넣어주면 되고, Decoder의 경우에도 mask token을 concat한 다음 random shuffle의 역 과정 (=unshuffle) 을 거치기만 하면 됩니다. 즉, masked image modeling을 위한 masking, shuffle의 과정에 sparse operation을 사용하지 않기 때문에 빠르다고 주장합니다.
✔️ ImageNet Experiments
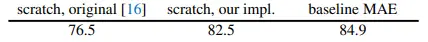
저자들은 ViT-L를 baseline으로 설정하였으며, original ViT 대비 strong regularization을 적용하였습니다. 여기서의 MAE는 fine-tuning 성능을 기록하였는데, 200 epoch를 학습한 scratch ViT에 비해 MAE는 단 50epoch만으로 2.4%p 높은 성능을 달성했습니다. 다음으로는 다양한 ablation study를 바탕으로 MAE의 특성들을 밝히고 있습니다.
Main Properties
Masking ratio
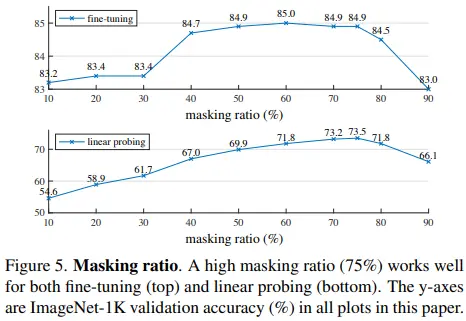
Masking ratio가 상대적으로 높은 수치인 75%에서 linear probing, fine-tuning 모두 좋은 성능을 보임을 알 수 있습니다. 이는 BERT의 15%, iGPT의 20%, ViT의 50% 보다도 높은 수치입니다.
또한, linear probing과 fine-tuning의 성능 trend의 차이를 확인할 수 있습니다. Linear probing은 75%까지 성능이 상승하다가 하락하는 반면, fine-tuning은 40%부터 80%까지 준수한 성능을 보이고 있습니다.

MAE가 높은 masking ratio에서 masked patch를 그럴싸하게 추론해내는 것은 Figure 4에서 확인하실 수 있습니다. 심지어 85%까지 높이더라도 어느 정도 reconstruction하는 것을 확인할 수 있죠. 저자들은 MAE가 유용한 representation을 학습했기에 이러한 추론 능력을 갖게 되었다고 추측합니다.
Decoder design
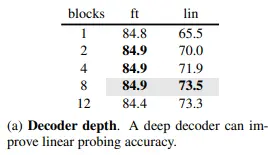
위 결과를 보면, decoder의 depth가 어느정도 되어야 linear probing 성능이 나오는 것을 볼 수 있습니다. 이는 pre-training 단계에서 reconstruction 역량을 학습하기에 decoder의 depth가 충분하지 못해, recognition을 담당하는 encoder의 일부 layer까지 영향을 줄 수 있기 때문입니다. 즉, encoder가 온전히 recognition에 집중하지 못해서 backbone을 freeze하는 linear probing의 성능이 낮아지게 된다고 주장합니다.
흥미로운 점은 fine-tuning 성능은 Transformer block을 단 1개만 사용하더라도 성능 하락이 거의 없는 수준입니다. 만약 fine-tuning 성능만 중요하다면, decoder depth를 얕게 하여 pre-training cost를 줄이는 것이 가능합니다.
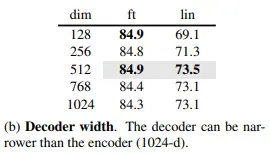
Decoder width 실험에서도 depth와 어느 정도 비슷한 양상을 보여주고 있습니다.
Decoder design을 종합하면, decoder는 8 blocks, 512 dim 에서의 성능이 가장 좋다고 나오는데요. 이는 encoder의 24 blocks, 1024 dim에 비하면 경량화된 상태입니다. 뿐만 아니라, mask token이 decoder에서만 학습되는 것을 고려한다면, pre-training cost가 줄어든다는 것을 알 수 있습니다. 즉, 속도, 성능 모든 측면에서 lightweight decoder design이 좋다고 할 수 있습니다.
Mask token

앞서 encoder는 mask token을 생략한다고 했는데요. 이는 성능 면에서도 좋은 결과를 보여주고 있으며, 특히 linear probing 성능의 차이가 심한 것을 볼 수 있습니다. Mask token은 실제 이미지가 아니기 때문에 encoder의 학습을 방해하는 결과를 가져오고, 이것이 linear probing 성능 차이로 드러난다고 저자들은 이야기합니다. 당연히 FLOPs 측면에서도 효율적임을 알 수 있습니다.
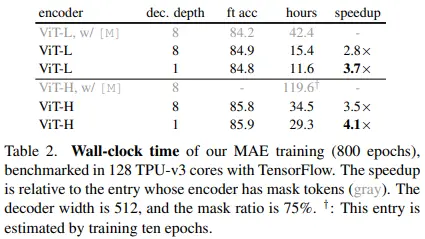
결국, encoder skip mask token + lightweight decoder를 적용하면 fine-tuning 성능은 유지하면서 pre-training 속도 향상이 가능하다는 것을 알 수 있습니다.
Reconstruction target
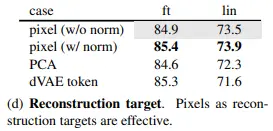
Pixel w/ per-patch normalization 성능이 가장 좋은 것으로 나옵니다. 하지만 회색 음영을 보시면 ablation study에서는 patch norm을 적용하지 않은 것을 default로 설정했습니다. (추측컨데, ablation 실험이 다 끝나고 per-patch normalization을 적용했더니 성능이 잘 나오지 않았나 싶습니다. Ablation 실험 이외에는 per-patch normalization을 적용한 것으로 보입니다.)
Pixel w/ per-patch normalization은 말 그대로, target 이미지를 patch 단위로 쪼갠 후 patch 단위로 normalization이 적용된 pixel을 예측하는 것입니다. 저자들은 per-patch normalization을 통해 local contrast를 향상시킬 수 있다고 주장합니다. 개인적으로는 ViT가 patch 단위로 normalization하기 때문에 더 좋은 성능을 보인 것이 아닌가 싶습니다.
또 다른 실험으로 PCA를 활용했습니다. 224 이미지에 16 patch로 쪼갤 경우, 1개의 patch는 196 size를 갖게 됩니다. 여기에 PCA를 적용해서 96 차원으로 embedding 시킨 결과를 target으로 학습하는 방식을 적용했습니다. (왜 96인가는 나와있지 않습니다.) 생각보다 성능 하락이 크지 않았다는 점은 의외인 것 같습니다.
저자들은 앞선 2개의 실험 결과를 바탕으로, MAE는 high-frequency가 필요하다고 주장합니다. (PCA로 축소한 차원에 따른 성능 하락은 이 결론과 매칭되는데, per-patch normalization 실험은 어떤 이유로 언급하고 있는지 잘 모르겠습니다.)
그 다음으로, BEiT의 DALL-E tokenizer 실험을 합니다. 이때의 decoder는 cross-entropy loss를 사용하여 token indices를 예측하는 task로 학습했는데요. 보시면, patch-norm을 하기 전보다 fine-tuning 성능이 좋은 것을 볼 수 있습니다. 이에 대해 저자들은 그럼에도 patch-norm을 적용하면 MAE의 fine-tuning 성능이 개선되고, MAE는 tokenizer가 추가로 필요하지 않다는 점에서 BEiT보다 더 좋다고 주장합니다.
Data augmentation

None은 center-crop만 적용했음을 의미하고, 나머지는 horizontalflip이 포함되어 있습니다. 놀라운 점은 center-crop만으로도 성능 하락이 크지 않았다는 점입니다. 이는 매 iter마다 적용되는 random masking의 효과로, augmentation 없이도 충분히 training regularization이 가능하다는 것을 보여줍니다. 특히, augmentation에 크게 의존하는 contrastive learning과 비교하여 장점이라고 할 수 있습니다.
Mask sampling strategy

BEiT에서 적용했던 block-wise masking과 grid masking을 대조군으로 실험했습니다. 다른 masking 대비 random masking의 성능이 좋은 것을 알 수 있고, 저자들이 말하길 block masking을 적용했을 때 training loss가 불안정했고 reconstruction 결과가 blurry했다고 합니다.
Training schedule
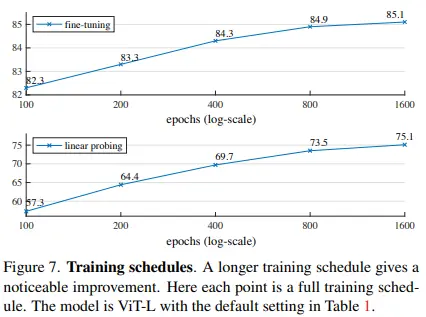
Ablation study에서는 800 epoch를 baseline으로 실험했습니다. 놀라운 점은 1600 epoch 까지도 saturation 현상을 찾아볼 수 없었다고 하는데요. 이는 300 epoch에서 saturate되었던 MoCo-v3와 비교되는 부분입니다.
Comparisons with Previous Results
Self-supervised methods
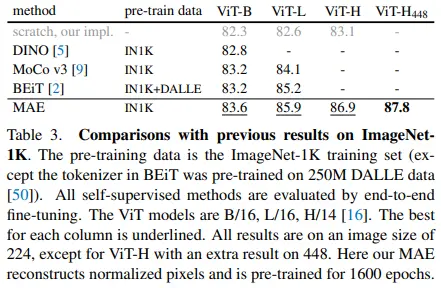
최신 self-supervised learning method인 DINO, MoCo-v3, BEiT 보다 좋은 성능을 보입니다. 그리고 ViT-H (448 size)는 vanilla ViT network로 당시 SOTA 였던 VOLO (512 size)의 성능도 뛰어넘었습니다.
또한, BEiT 대비 1 epoch 기준 3.5배 빠르며, MoCo-v3 대비 전체 epoch 기준 1.16배 빠르다고 합니다.
Supervised pre-training
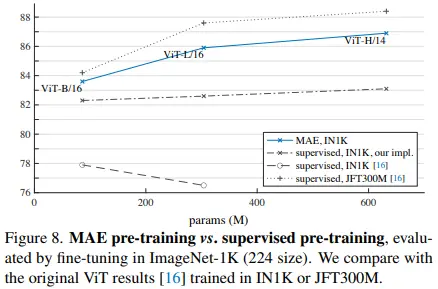
먼저, 아래의 점선 2개를 보면, 저자들의 strong regularization이 ViT training에 적합한 것을 볼 수 있습니다.
또한, 가장 위에 있는 JFT-300M data로 학습한 original ViT 성능보다는 낮지만, MAE가 ImageNet-1K 만으로 준수한 성능을 보이고 있습니다.
Partial Fine-tuning
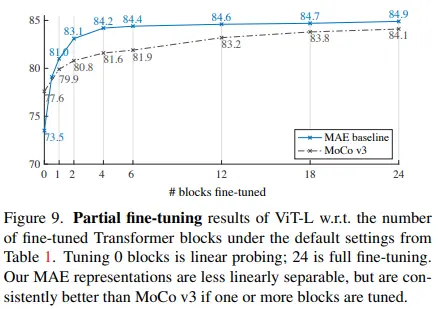
MAE의 fine-tuning 성능은 잘 나오는 반면, linear probing의 성능은 MoCo-v3 대비 저조했습니다. 저자들은 linear probing이 비선형성을 평가하지 못하기 때문이라 생각했고, How transferable are features in deep neural networks? 논문의 partial fine-tuning을 적용해보기로 합니다. 그 결과, 단 1개의 block만 추가로 학습하더라도 이전의 73.5%에서 81.0%로 급격하게 성능이 향상했습니다. 심지어, 1개의 block 안에 있는 MLP sub-block만 추가 학습하더라도 79.1%라는 성능을 보였습니다. 결론적으로 MAE의 representation은 선형적으로 분리하기 어렵긴 하지만, 강력한 비선형 feature를 추출한다고 주장합니다.
✔️ Transfer Learning Experiments
Downstream task에 대한 transfer learning 성능도 좋게 기록되어 있습니다. 표와 설명은 생략하겠습니다.
✔️ Discussion and Conclusion
정리하면, MAE는 알고리즘이 간단하고, 학습 속도가 빠르며, 모델 확장성이 좋은, vision 도메인에서 masking을 활용한 self-supervised method 입니다.
저자들이 말하길 이미지는 단어의 시각적 유사체일뿐, 의미론적인 분해가 불가능한, 기록된 빛에 불과하다고 합니다. 그렇기에 MAE는 높은 비율로 의미를 형성하지 않을 random patch를 제거했고, 의미를 형성하는 단위가 아닌 pixel level에서의 reconstruct를 하며 학습하도록 설계되었습니다. 이러한 학습 방식에도 불구하고 MAE는 복잡하고 전체적인 reconstruct를 추론해내는 능력을 가졌고, visual concept도 잘 학습하는 것으로 보입니다. 이는 앞으로 연구될 가치가 있는 MAE의 hidden representation 특성이므로 future work로 제안하고 있습니다.
아래의 내용은 appendix의 implementation details 부분만 영어 표현 그대로 정리해둔 것 입니다. MAE 리뷰는 여기서 마치겠습니다.
✔️ Appendix
ImageNet Experiments
ViT architecture
- Encoder ends with LN
- Sine-cosine positional embeddings
- Not use relative position or layer scaling (which are used in the code of BEiT)
- For pre-training, append an auxiliary dummy token to the encoder input for ViT design
Pre-training
- Not use color jittering, drop path, or gradient clip
- Use xavier_uniform initialization
- Linear LR scaling rule: lr = base_lr * batch_size / 256
End-to-end fine-tuning
- Follow common practice of supervised ViT training
- Use layer-wise lr decay (following BEiT)
Linear probing
- Follow MoCov3
- Regularization is in general harmful for linear probing
- Not use mixup, cutmix, drop path, or color jittering
- Set weight decay as zero
- Be beneficial to normalize the pre-trained features when training the linear probing classifier
- Adopt an extra BatchNorm layer without affine transformation
- The layer does not break the linear property
- It is essentially a reparameterized linear classifier
Partial fine-tuning
- Follow end-to-end fine-tuning setting
- Set the numbers of fine-tuning eochs as {50, 100, 200} and use the optimal one for each number of blocks tuned
Supervised Training ViT-L/H from Scratch
- Follow original ViT
- Weight decay: 0.3
- Batch size: 4096
- Long warmup
- Beta_2 = 0.95 (following iGPT)
- Use the regularizations and disable others (following Early convolutions help transformers see better)
- Follow original ViT
Object Detection and Segmentation in COCO
- Follow Benchmarking Detection Transfer Learning with Vision Transformers
- ViT + FPN + Mask R-CNN
- Multi-scale map: equally divide stacked Transformer block into 4 subsets and apply convolutions to upsample or downsample the intermediate feature maps for producing different scales
- Search for LR, weight decay, drop path rate, and epoch
- Follow Benchmarking Detection Transfer Learning with Vision Transformers
Semantic Segmentation in ADE20K
- UperNet (following BEiT)
- Epoch: 100
- Batch size: 16
- Search for LR
- For fair comparison, turn on relative position bias only during transfer learning, initialized as zero
Additional Classification Tasks
- Follow end-to-end fine-tuning setting
- Adjust LR and epoch