[논문리뷰] data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language (ICML ‘22 Oral)
이번에 리뷰할 논문은 ICML 2022에 accept된 data2vec입니다.
저자분들은 주로 facebook (meta)에서 speech,sequence 도메인의 self-supervised learning을 연구하시던 분들이 참여하셔서, 전반적으로 speech 도메인의 개념과 용어가 자주 등장합니다.
저는 vision 도메인 지식만 보유하고 있어서, speech와 NLP 도메인은 설명이 부족할 수 있다는 점 참고해주시면 감사하겠습니다.
✔️ Abstract
Data2vec의 pre-training objective는 masked input에서 추출된 partial representation으로 origin input에서 추출된 teacher representations을 예측하는 방식이며, (제가 생각하는) 핵심 구성요소는 다음과 같습니다.
Siamese Network with EMA update (from student to teacher)
Student Input : a masked view of the input
Teacher Input : original (= unmasked) input
Layer-averaged Target : teacher의 last representations(= feature maps) top-K의 평균을 target으로 학습합니다.
Contextualized latent representations : visual token, word, unit of human speech 등의 modality-specific discrete target이 아니라 representation 자체를 target으로 하며, teacher의 input이 unmasked되어 있고, ViT의 self-attention 덕분에, input이 갖는 전체적인 맥락이 representation에 잘 담긴다고 주장합니다.
여담으로 context 라는 용어도 wav2vec에서 온 것으로 보입니다.
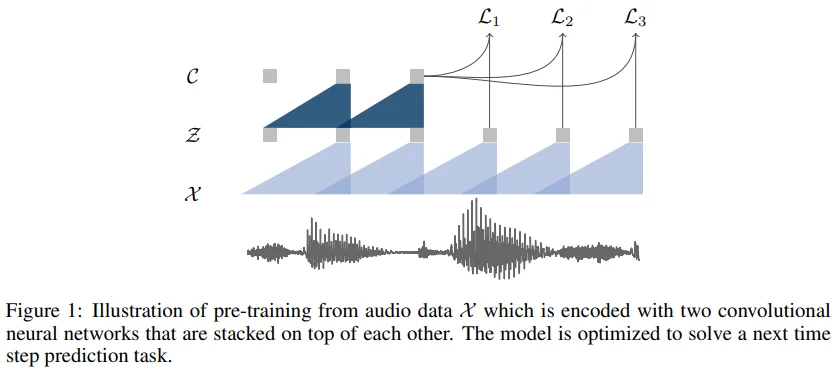
위 figure는 wav2vec의 network를 설명하고 있습니다. 보시면 $C$로 표기된 context network라는 개념이 나오는데, encoder network의 output인 latent representations을 여러 개 받아서 하나의 contextualized tensor로 mapping하는 network라고 생각해주시면 됩니다. 저자들이 생각하기에 data2vec에서 teacher network의 역할이 wav2vec의 context network와 비슷하다고 생각하여, contextualized target으로 용어를 확장해서 사용하는 것 같습니다.
✔️ Related Work
Self-supervised Learning in Computer Vision
Augmented view에 기반하여 contrasting representation을 self-supervised learning하는 여러 연구들이 존재합니다. 그중 BYOL이 representation 자체를 target으로 학습한다는 점에서 data2vec과 유사합니다. 하지만 data2vec은 top representation뿐만 아니라, layer-averaged target으로 학습한다는 차이가 있습니다.
또한, ViT를 backbone으로 masked prediction objective를 학습하는 여러 연구들도 존재합니다.
Pre-training 이전에 visual token을 미리 학습 (= offline tokenizer) : VQ-VQE, DALL-E
Pre-training 과정에 visual token도 같이 학습 (= online tokenizer) : iBOT
위 연구들과는 달리, data2vec은 context를 내재한 latent representations를 예측한다는 차이점이 있습니다. 즉, data2vec은 visual token, pixel value처럼 discrete한 단위에 국한되는 것이 아니라, 전체적인 context를 내재한 representations을 target으로 학습한다는 차이점이 있습니다.
Self-supervised Learning in NLP
Masked prediction task로 학습하는 가장 유명한 모델로 BERT가 있습니다. BERT는 word, sub-word 같은 discrete token을 예측하는 학습 방식을 사용하기 때문에, word 구분이 용이한 대부분의 언어에 적용하기 쉽고, smaller BERT-style model에 distillation이 용이하다는 장점을 갖게 됩니다.
BERT와 대비하여 data2vec은 다음의 2가지 장점을 가진다고 주장합니다.
Target이 predifine되지 않기 때문에, token 개수와 같은 제약으로부터 자유로워집니다.
Original input으로부터 추출된 representation target을 예측하므로 전체적인 맥락을 고려할 수 있습니다.
Self-supervised Learning in Speech
Speech 도메인에서는 autoregressive model, bi-directional model 등이 주로 연구되어 왔습니다. 그중 (저자들이 참여했던 논문들인) wav2vec 2.0와 HuBERT를 언급하고 있는데, discrete unit of speech를 예측하는 이들과 달리 data2vec은 contextualized representations을 예측한다는 점에서 novelty가 있다고 주장합니다.
Multimodal Pre-training
Data2vec이 multimodal training을 수행한다는 것은 아니고, 다양한 modality의 self-supervised leraning objectvie를 통합하는 것에 의의가 있다고 주장합니다.
✔️ Introduction
저자들은 각각의 modality 내에서 활발히 진행되던 self-supervised learning objective를 통합하고자 했습니다. 이와 관련하여 modality-specific과 비교하여 준수한 성능을 갖는 general architecture가 존재할 수 있음을 밝힌 DeepMind의 Perceiver IO 논문도 언급하고 있습니다. (주로 speech 연구를 하시던 분들이 vision, language까지 연구를 확장한 계기이지 않을까 싶습니다.)
(뇌피셜이지만) 조금 더 디테일하게 보면,
- 각각의 modality에서 효과가 검증된 masked prediction objectvie로,
- Modality-specific discrete target 대신, 다양한 modality에 적용될 수 있는 representation target을 예측하며,
- 그렇기에, representation target은 unmasked input에서 추출될 필요가 있었을 것 (성능 면에서도 unmasked input이 masked보다 good)
- 이러한 구조를 효과적으로 학습하는 siamese network with EMA 구조를 적용했다고 보여집니다.
- 또한, layer-averaged target은 wav2vec 2.0 실험 결과에서 insight를 얻었다고 합니다.
✔️ Method
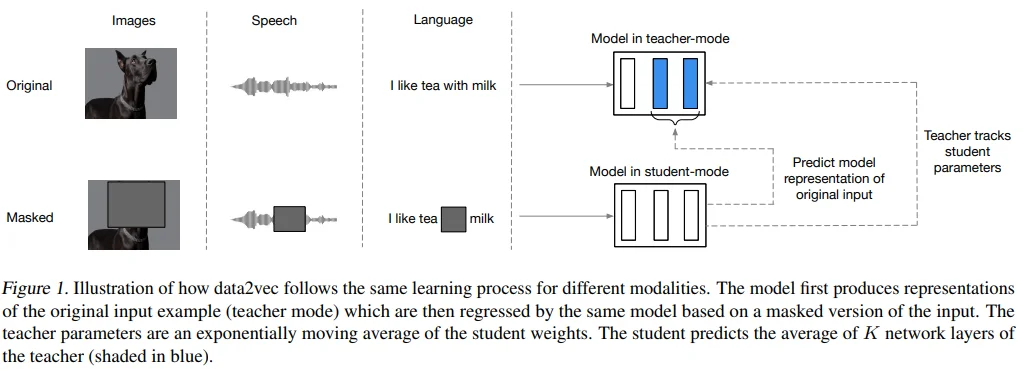
Figure 1을 보면 data2vec의 pre-training 과정을 한 눈에 볼 수 있습니다. 크게 보면 data2vec은 masked input을 보고 original input의 representation top-K 평균을 예측하는 학습 방식이, image, speech, language에 모두 효과적임을 보여주고 있습니다. 자세한 설명은 아래 각 항목에서 하겠습니다.
Model Architecture
Data2vec은 standard Transformer에 modality-specific encoding을 사용합니다. (data2vec은 objective를 통합한 것일뿐, encoding까지 통합하지는 못 했습니다.)
Vision (follow BEiT) : patchify, replace mask token, add class token, then positional embedding (PE)
- Official data2vec code에는 PE이 없는 것으로 보이는데, 그보다 먼저 공유된 것으로 보이는 링크와 official BEiT code에는 PE이 포함되어 있습니다.
- data2vec 2.0 코드와 섞이면서 PE이 실수로 사라진건지, 원래 적용되지 않았는지는 잘 모르겠습니다.
Speech (follow wav2vec 2.0) : multi-layer 1D CNN (mapping 16kHz to 50hz)
Language (follow BERT) : obtain sub-word units, then embedded in distributional space via learned embedding vectors
Masking
일반적으로 MASK token을 추가하는 과정과 동일합니다. 자세히 설명하자면 embedding된 input token sequence 중 일부를 학습 가능한 MASK token으로 replace합니다.
Vision (follow BEiT) : block-wise masking
Speech (follow wav2vec 2.0) : spans of latent speech representations
Language (follow BERT) : token
Training Targets
Data2vec의 target은 contextualized representations이며, 이는 masked input 중 masking되지 않은 information + Transformer의 self-attention으로부터 얻은 other information을 갖고 있다고 주장합니다.
Teacher Parameterization
Teacher network는 직접 학습하는 것이 아니라, student network로부터 EAM된 parameter로 update하는 방식입니다.
$\tau$는 EMA 비율을 의미합니다. linear warmup scheduling을 적용함으로써, 좋은 representation을 추출하지 못하는 pre-train 초기 단계에서 빠른 update가 가능하게 합니다. (Vision에는 tau scheduling 적용 X)
Targets
Training target은 teacher network의 top K block의 평균입니다. 이렇게 평균을 target으로 사용하는 것은 wav2vec 2.0에서 영감을 얻었다고 합니다.
그리고 top K 평균을 계산하기 전에 각 block 단위로 normalize하는 과정이 있는데요. 이렇게 함으로써 constant representation으로 collapsing되는 것을 막을 수 있고, 특정 block의 representation이 과하게 영향을 주는 현상을 방지할 수 있다고 합니다.
Speech : instance normalization
Small stride로 인해 인접한 representation끼리 연관성이 높기 때문에, 학습 가능한 파라미터가 없는 instance norm을 사용한다고 합니다.
Vision, Language : layer normalization
Objective
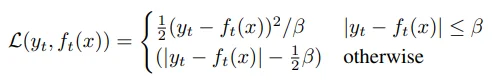
Smooth L1 loss를 사용합니다. 특이한 점은 $B$를 target과 prediction의 차이와 비교하여, squared loss와 L1 loss 중 하나로 결정한다는 것입니다. 위 loss는 outlier에 덜 민감하다는 장점이 있고, $B$ tuning이 필요하다는 단점이 있습니다.
✔️ Results
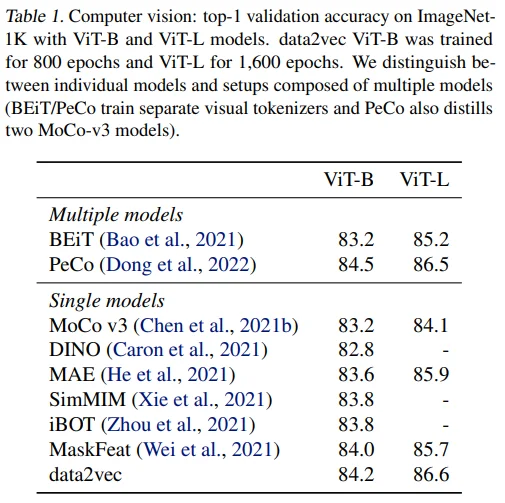
Computer Vision
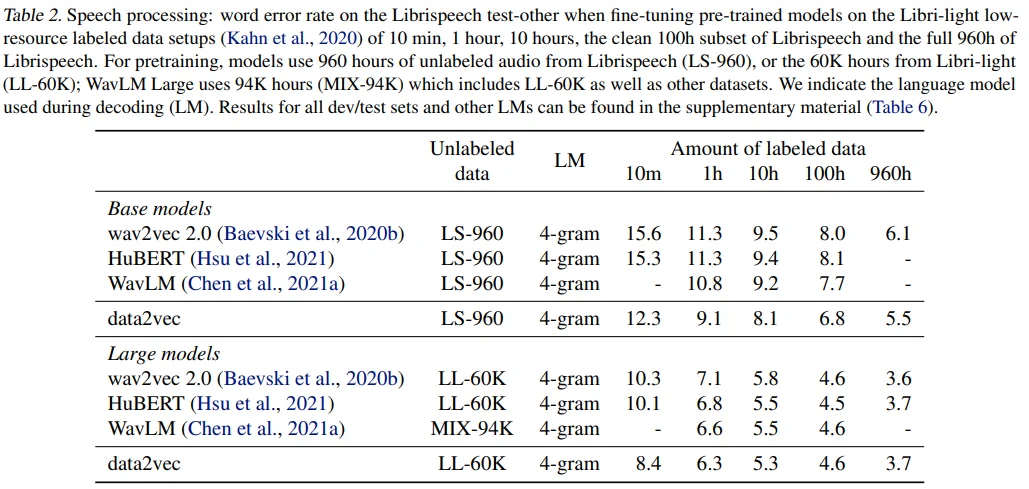
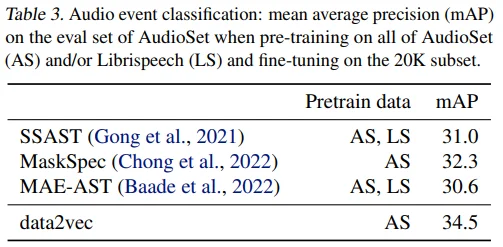
Speech and Audio Processing
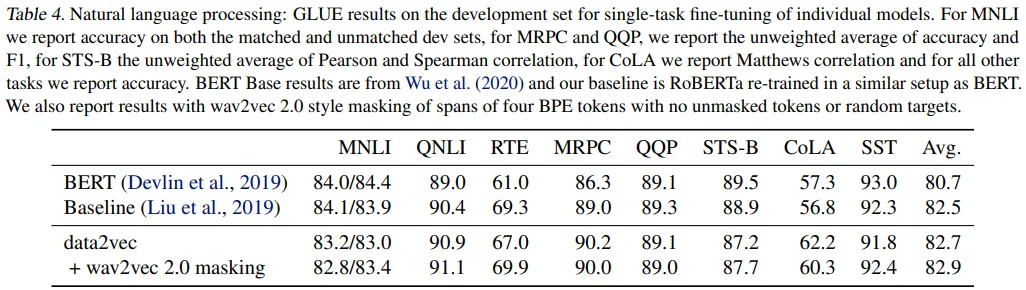
Natural Language Processing
Ablations
Layer-averaged Targets
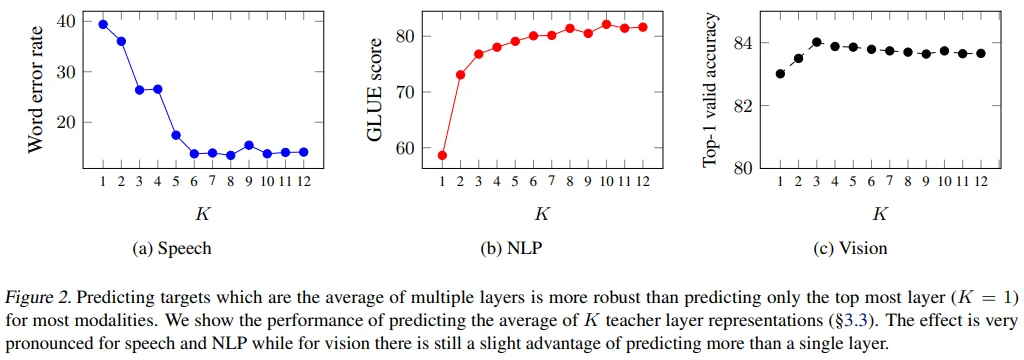
Top K가 1인 경우는 last representation 1개를 target으로 사용하는 경우입니다. Speech와 NLP에서는 K에 비례하여 성능이 높아지는 것을 볼 수 있지만, vision 도메인에서는 K=3까지 성능이 높아지다가 소폭 낮아지는 것을 볼 수 있습니다. 즉, wav2vec 2.0에서 영감을 얻은 layer-averaged target이 다른 도메인에서도 효과적이라는 결론을 보이고 있습니다. (Vision에서도 K=12가 K=1보다 성능이 꽤 높음)
Target Contextualization
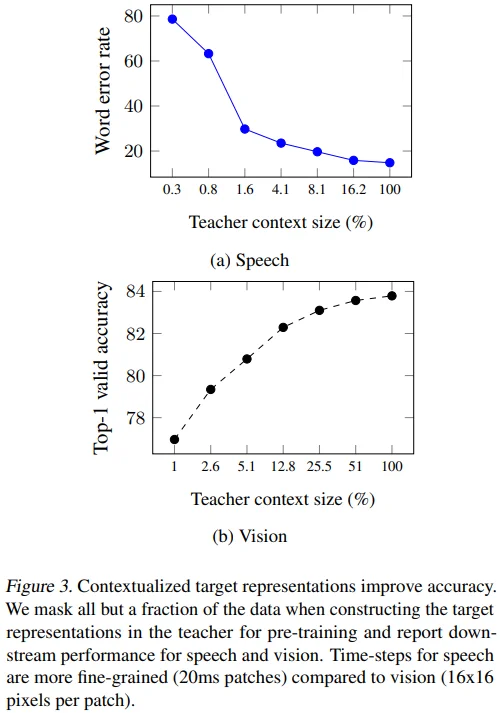
Pre-train 단계에서 target input masking 비율을 바꿔가며 실험했습니다. 저자들의 주장대로 100%를 사용할 때 성능이 가장 좋긴 합니다. (하지만 NLP 결과도 없고, 왜 좋은지에 대한 이유는 가설에 머무르는 것 같아서 아쉬움도 남네요.)
Target Feature Type
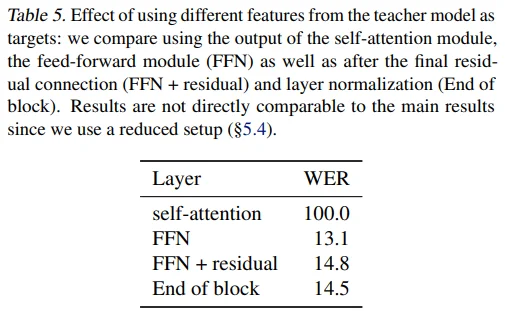
Speech 도메인에서 target feature별 성능을 기록했습니다. Self-attention 직후의 feature는 사용이 불가능한 수준이었는데, 저자들은 그 이유가 다른 time-stamps에 과하게 연관되어 있고 residual connection도 없기 때문이라고 추정하고 있습니다.
- 개인적인 생각으로는,
- Speech 도메인의 경우, input signal 자체만으로도 correlation이 높기 때문에 self-attention 직후보다는 FFN 이후의 feature가 self-supervised 학습이 잘 되는 것 같고,
- Residual connection을 통해 contextualized target을 예측하도록 하는 것이 학습에 도움될 것 같습니다.
- 하지만 Vision, NLP 등 다른 도메인 실험 결과가 없다는 점은 아쉽습니다.
✔️ Discussion
Modality-specific Feature Extractors and Masking
Data2vec은 다양한 modality에 적용할 수 있는 self-supervised 학습 방식을 제안했다는 의의를 갖지만, feature 추출과 masking은 modality-specific하다는 한계를 가집니다. 이는 각 modality의 특징이 매우 다르기 때문에 어쩔 수 없다는 주장을 하고 있으며, 그에 따라 masking 전략도 다를 수 밖에 없다는 논지를 이어갑니다.
예를 들면 speech 도메인은 high resolution input이라서 multiple conv layer로 feature을 추출했고, 인접한 feature 간 연관성이 높기 때문에 선정된 index부터 10 time-stamps를 masking하는 전략이 학습에 도움이 되었습니다.
반면 NLP 도메인은 lower resolution input이기 때문에 상대적으로 간단한 lookup table (tokenizer)을 활용한 embedding 방식으로 feature를 추출했고, 상대적으로 인접한 feature 간 연관성이 낮기 때문에 random하게 masking token을 결정하는 masking 전략이 학습에 도움이 되었습니다.
앞서 언급했던 perceiver IO 논문은 이러한 modality별 feature 추출 방식을 통합하여 준수한 성능을 보였지만 supervised learning에 그친다는 한계를 가집니다. 따라서 저자들은 perceiver IO와 data2vec이 상호 보완될 여지가 있다고 언급하고 있습니다.
Structured and Contextualized Targets
지난 self-supervised learning 연구와의 가장 큰 차이점은 바로 contextualized target이라고 주장합니다.
Vision 도메인의 BYOL, DINO에서도 masking이 적용되지 않은 original input으로 target representation을 학습하지만, 이 두 연구는 augmentation을 활용한 transformation-invariant representation을 학습한다는 점에서 다릅니다.
Speech 도메인의 HuBERT도 clustering과 codebook을 활용하여 discrete target을 학습한다는 점에서 유사점이 있지만, data2vec은 target unit의 수를 조절할 수 있고 current input 맥락이 반영된 target을 만들어낸다는 차이가 존재합니다.
NLP 도메인의 경우 pre-defined target unit을 사용하지 않는 것은 data2vec이 처음이라고 주장합니다. 특히, 단어 구분이 명확하지 않은 아시아권의 일부 언어에 효과적일 수 있고, contextualized target은 self-supervised task를 효과적이게 만든다고 주장합니다. 즉, 같은 단어일지라도 어떤 맥락이냐에 따라 그 뜻이 달라지기 마련인데, data2vec은 이러한 것들을 고려한 학습이 가능해집니다.
Representation Collapse
Understanding Dimensional Collapse in Contrastive Self-supervised Learning 논문에 따르면, representation을 target으로 하기 때문에 비슷한 representation을 갖는 경우 문제가 될 수 있다고 합니다. 이러한 점을 해결하고자 wav2vec 2.0에서는 동일한 target representation을 각각 positive, negative sample로 학습하였으며, BYOL은 teacher network의 gradient로 학습하는 것이 아니라 student network의 parameter로 update하는 siamese 구조를, VicReg은 다른 representation 사이에 variance를 만들어내는 loss 함수를 추가했습니다.
저자들이 분석한 collapse가 발생하는 시나리오는 다음과 같습니다.
- Learning rate이 너무 크거나, warmup epoch이 너무 작은 경우
- EMA update value인 $\tau$가 너무 작은 경우
- Target 간 correlation이 너무 높아 longer span을 masking해야 하는 경우
1,2번은 hyper-parameter tuning을 통해 어느 정도 해결이 가능하지만, 특히 speech 도메인이 마지막 시나리오에 해당된다고 판단하였습니다. 이를 해결하고자 BYOL로부터 아이디어를 얻어,target representation을 sequence, batch 단위로 normalize함으로써 variance가 생길 수 있도록 했습니다. (Target이 많이 correlate되어 있지 않은 vision, NLP 도메인의 경우는 BYOL의 siamese 구조를 적용하여 해결했다고 합니다.)
Conclusion은 내용이 많이 겹치는 것 같아서 제외했습니다.
아래는 실험 정보를 그대로 적어둔 것입니다. 리뷰는 여기서 마치겠습니다.
✔️ Experimental Setup
전체 공통
- EMA update : fp32
- Adam optimizer
Model architecture
- data2vec base : L=12, H=768
- data2vec large : L=24, H=1025
Computer Vision
- Embedding : follow ViT
- Masking : follow BEiT (masking 비율은 기존 40%에서 60%로 높였음)
- Augmentation : follow BEiT (randomly, resized crop + horizontal flip + color jitter)
- $B$ : 2 (loss parameter)
- K : 6 (number of representations)
- Stochastic depth rate : 0.2
Size-specific
- Epochs : base(800), large(1600)
- Batch size : base(2048), large(8192)
- Warm up (epochs, max LR) : base(40, 0.002), large(80, 0.001)
- EMA update rate : base(0~800:0.9998), large(0~800:0.9998, 800~1600:0.9999)
Finetune
- Epochs : base(100), large(50)
- Warm up (epochs, max LR) : base(20, 0.004), large(5, 0.004)
Speech Processing
- Embedding : follow wav2vec 2.0 (7개의 conv layer)
- Masking : follow wav2vec 2.0 (p=0.065로 선정한 index의 이후 10 time-steps masking, 결과적으로 전체의 약 49% masking)
- EMA update rate : 0.999를 시작으로 30000 time-steps 동안 0.9999까지 linear scheduling 적용
- K : 8
- Max LR : 5e-4
- Tri-stage scheduler
- linear warmup : 0~3%
- hold : 3~97%
- linear decay : 97~100%
Natural Language Processing
- Follow RoBERTa code in farseq
- Embedding : a byte-pair encoding
- Masking : follow BERT (전체 중 15%에 대해서, mask token (80%) + random token (10%) + unchanged (10%))
- Not use next-sentence prediction task
- EMA update rate : 0.999를 시작으로 100000 step 동안 0.9999까지 linear scheduling 적용
- K : 10
- $B$ : 4
- Max LR : 2e-4
- Batch size : 256 sequences (each sequence max token: 512)
- Tri-stage scheduler
- linear warmup : 0~5%
- hold : 5~85%
- linear decay : 85~100%