[논문리뷰] AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition (NIPS ‘22)
Introduction
General한 성능을 보장하는 weight를 얻기 위해서는 pre-train, fine-tune 단계에서 접근 가능합니다.
Pre-train: self-supervised learning, representation learning 등의 분야에서 연구되고 있으며, 그 기저에 깔린 생각은 “너가 어떤 task를 풀지는 모르지만 input image로부터 좋은 represention을 뽑아낼 수 있도록 미리 학습시키자” 입니다.
Fine-tune: pre-train 이후의 weight를 효과적으로 fine-tune 하자는 방향으로, AdaptFormer가 이에 속합니다.
그렇다면 이전의 튜닝 방법들은 어떤 단점이 있었을까요? 먼저 full fine-tuning의 경우, 각각의 task에 대해 매번 학습해야 한다는 점에서 general한 성능과는 거리가 있습니다. 또한, linear proibing도 딥러닝의 장점인 비선형성 학습을 하지 못한다는 단점이 존재합니다.
본 논문에서 제안하는 AdaptFormer의 contribution은 다음과 같습니다.
Full fine-tuning 대비 학습 파라미터가 0.2%에 불과한 AdaptFormer는 ViT를 adapting 할 수 있는 간단하고 효과적인 framework입니다.
학습 파라미터가 커지면 성능이 급격히 낮아지는 VPT(Visual Prompt Tuning)에 비해, AdaptFormer는 scale이 커져도 성능이 안정적입니다.
Full fine-tuning과 비교하여 준수한 성능을 보이며, 특히 Video 도메인에서 좋은 성능을 보입니다.
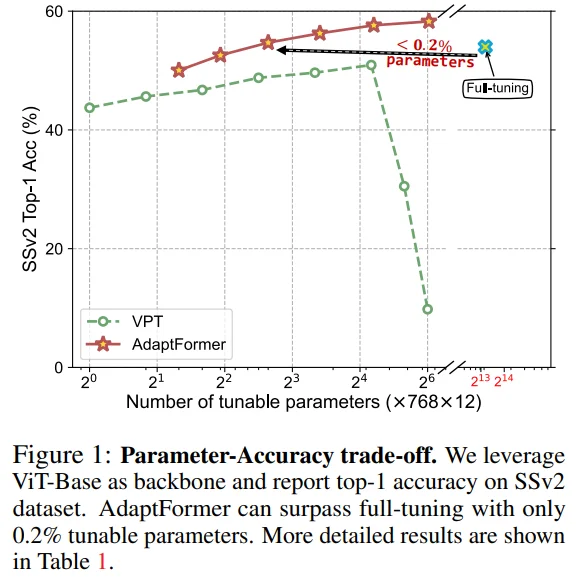
Figure 1: SSv2 dataset에서 학습 파라미터가 증가할 때 VPT의 성능이 떨어지는 반면, AdaptFormer는 안정적인 성능을 보이고 있으며 full fine-tuning에 비해 학습 파라미터가 매우 적다는 점도 확인할 수 있습니다.
Approach
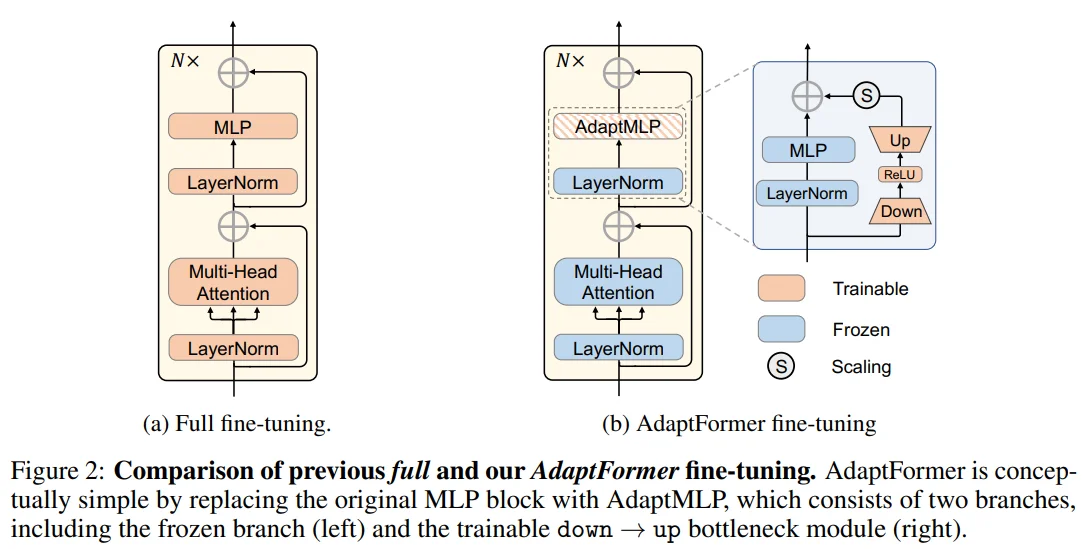
Figure 2: AdaptFormer는 기본적인 MLP block에 AdaptMLP라는 trainable branch를 추가하는 간단한 구조로 이루어집니다.
Down projection -> ReLU -> Up projection 을 거친 이후에 scale factor 만큼 resiudal connection 되는 구조로, trainable 파라미터의 양이 적고 residual connection 구조라는 점에서 다양한 task에 대한 fine-tuning이 용이해집니다.
Down -> Up 구조와 같은 bottleneck 구조를 적용하여 효율적으로 파라미터 수 조절이 가능합니다.
ReLU layer를 통해 비선형성 학습이 가능합니다.
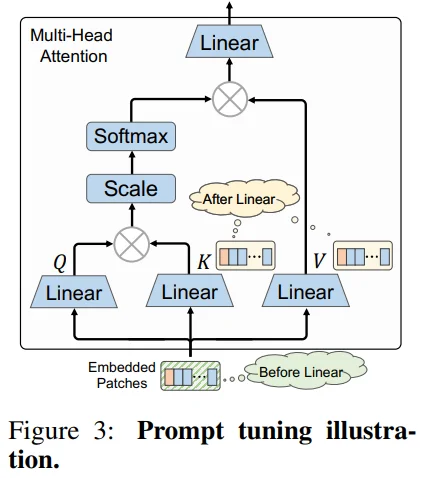
그렇다면 왜 하필 MLP block에 Adapter를 적용했는지에 대해서는 2가지 측면으로 답변하고 있습니다.
Efficient fine-tuning과 비슷한 목적으로 연구되었던 prompt-related 방식과 비교하여 확장성이 좋다고 주장합니다. Figure 3을 보면 Prefix-Tuning은 linear projection 이전에, 그리고VPT(Visual Prompt Tuning)은 linear projection 이후에 prompt를 tuning하고자 했습니다. 하지만, prompt-related 방식은 attention 구조 안에서 적용되므로, swin trasnformer나 PvT와 같은 특정 attention을 사용하는 모델에 적용되기 어렵습니다. 즉, FFN(MLP block)에 적용되는 AdaptFormer는 prompt-related 방식과 비교하여 상대적으로 확장성이 좋다고 할 수 있습니다.
또한, MLP block이 ViT에서 중요한 역할을 수행한다고 주장합니다. 그 근거로 인용한 Attention is not all you need 논문에서는 skip connection이나 MLP 없이는 Transformer의 output이 rank-1 matrix에 수렴한다고 합니다. (= token uniformity) (읽으면서 Poolformer나 MLP-like 모델이나 Attention을 개선하려 했던 여러 모델들을 생각해보면 인사이트 자체는 이해되는데, 그 근거가 조금은 빈약하다고 생각했습니다.)
Experiments
Model : ViT-B/16
Image
Pre-train dataset : ImageNet-21k
Pre-train recipe : supervised pre-trained model3 and MAE self-supervised model
Video
Pre-train dataset : Kinetics-400
Pre-train recipe : supervised and self-supervised pre-trained models from VideoMAE
Initialization
Down projection weight만 kaiming uniform init 적용
Down projection bias + Up projection weight/bias : zero init 적용
- Frozen pre-trained weight와 비슷하게 동작하게끔 zero init을 적용했다고 합니다.
아래 링크의 코드에 init_option을 lora라고 명시했는데, zero init과 관련 있어 보입니다. (아직 와닿지는 않네요..)
https://github.com/ShoufaChen/AdaptFormer/blob/main/models/adapter.py#L41-L48
Downstream task
Image : CIFAR-100(32x32), SVHN(32x32), Food-101(장축 512)
Video : SSv2, HMDB51(340×256)
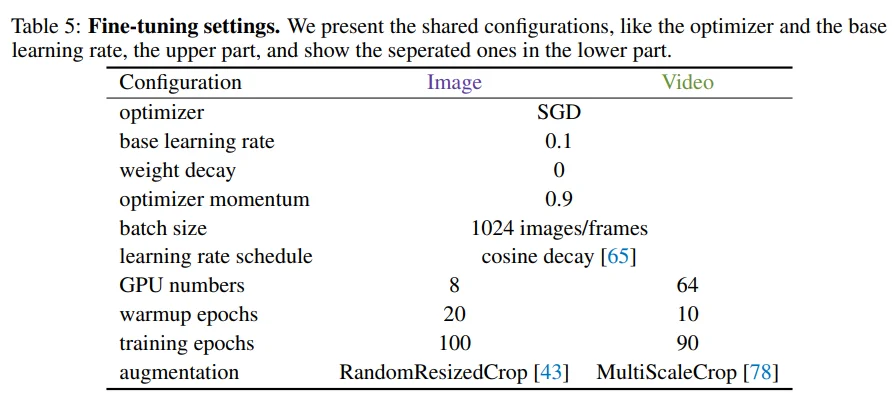
Table 5: fine-tuning recipe입니다. Image resolution이 낮은 dataset의 학습 안정성을 위해 SGD optimizer를 사용했다고 합니다.
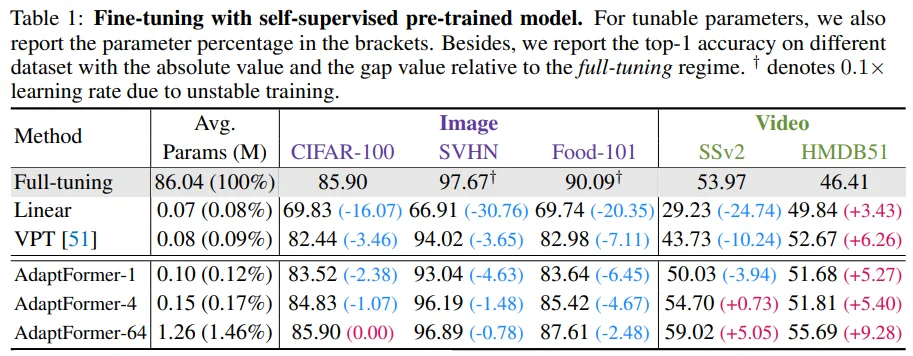
Table 1: Self-supervised learning인 MAE, VideoMAE로 pre-trian된 weight를 fine-tuning한 성능입니다. (AdaptFormer 뒤의 숫자는 Down-Up 과정에서 줄어드는 hidden dimension입니다.)
먼저 Image 도메인을 보면, fine-tuning 성능에 비해 linear probing 성능이 나쁜 MAE의 특징이 나타나고 있네요. 그리고 VPT에 비해 학습 파라미터가 많긴 하지만 더 좋은 성능을 보이면서, full-tuning에 준하는(?) 성능을 보이고 있습니다. (재미있는 부분은 image resolution이 32에 불과한 CIFAR-100과 SVHN 성능은 full-tuning과 비슷한데, 이미지 장축이 512인 Food-101 성능은 꽤 떨어진다는 점입니다.)
그리고 Video 도메인의 경우, Linear, VPT는 물론이고 Full-tuning보다 매우 좋은 성능을 보이고 있습니다.
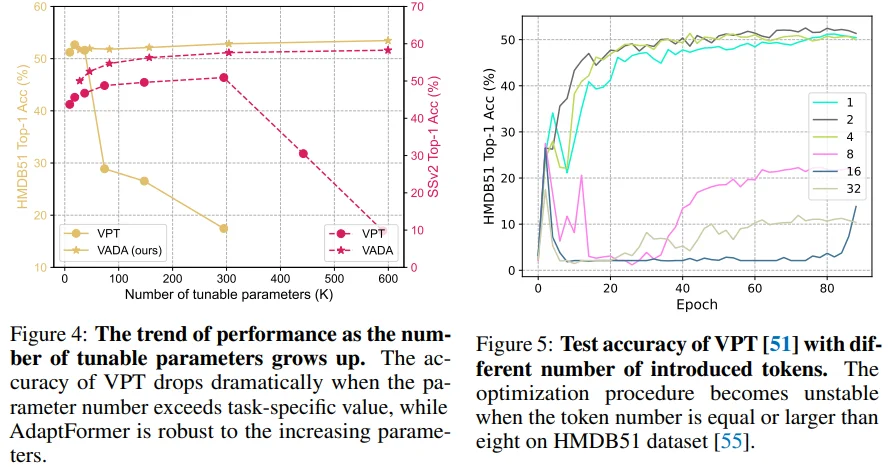
Figure 4 & Figure 5: HMDB51 dataset에서 학습 파라미터 양이 증가함에 따라 성능이 떨어지고 학습이 불안정해지는 VPT의 학습 양상을 확인할 수 있습니다.
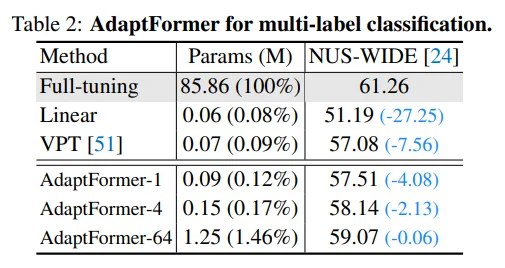
Table 2: NUS-WIDE dataset에 대한 multi-label classification 성능입니다. (성능이 잘못 기록된 것 같아서 이슈 남겨놨는데, 답글이 달리면 공유하겠습니다.)
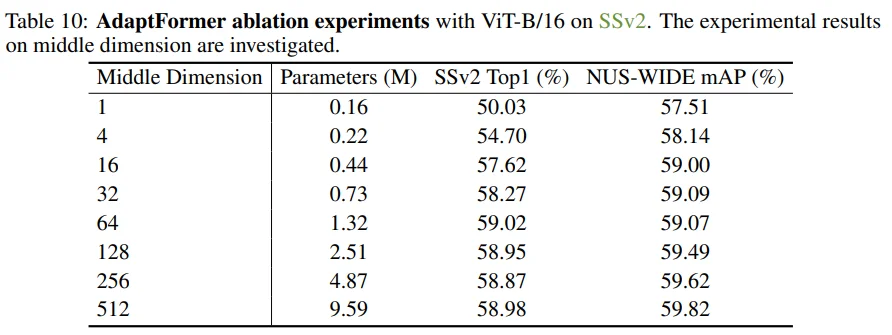
Table 10: Middle dimension은 dataset에 따라 다른 양상을 보이긴 하지만, 대체적으로 비례하는 모습을 보입니다.
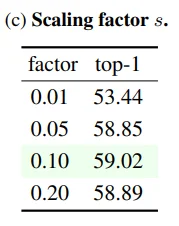
Table 3c: Scaling factor는 0.1에서 좋은 성능을 보였습니다. 추가로 SSv2 dataset에서만 확인되었다는 점, NLP에서는 상대적으로 높은 값(1 ~ 4)을 사용한다는 점도 참고하시면 좋을 것 같습니다.
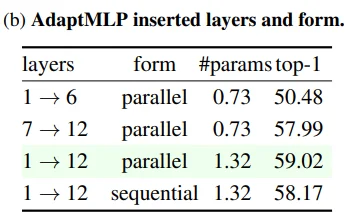
Table 3b: AdaptMLP branch 관련한 실험입니다. 흥미로운 점은 앞쪽(1->6)보다 뒤쪽(7->12)에 적용되었을 때 훨씬 좋은 성능을 보인다는 점입니다.
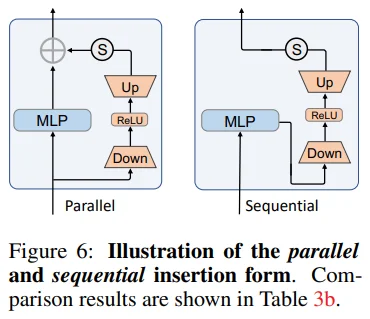
Table 3b & Figure 6: 그리고 sequential 보다 parallel form의 성능이 더 좋은 것을 볼 수 있습니다. AdaptFormer의 목적을 고려했을 때에도 parallel 형태가 더 알맞다고 여겨집니다.
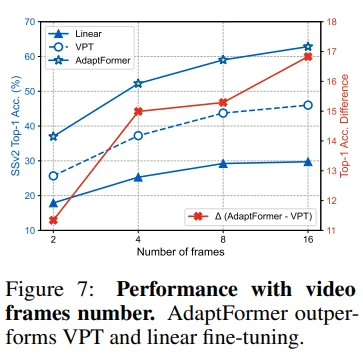
Figure 7: VPT와 비교해서 video frame 수가 많아짐에 따라 성능 차이 또한 커지는 모습입니다.
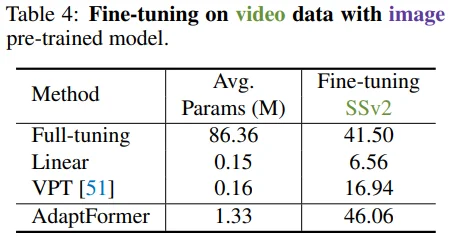
Table 4: ImageNet-21k로 pre-train된 weight를 SSv2로 fine-tune시켰습니다. 저자들은 이를 두고 AdaptFormer가 damain shift에 robust하다고 주장합니다.

Figure 8: last linear feature를 t-SNE 시각화한 결과입니다. 사실 이것만 보고는 AdaptFormer가 full fine-tune보다 확연히 더 잘 한다고 보기엔 어려운 것 같습니다.
Conclusion
Image, Video classification task에서 AdaptFormer의 준수한 성능을 보였으나, detection, segmentation task에 대한 연구를 하지 못한 것을 한계점으로 언급하고 있습니다.
Appendix
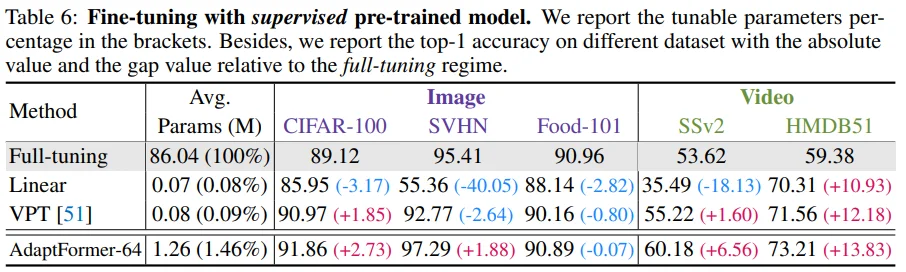
Table 6: Supervised learning으로 pre-train된 weight에서는 self-seupervised 때보다 더 좋은 성능을 보였습니다.
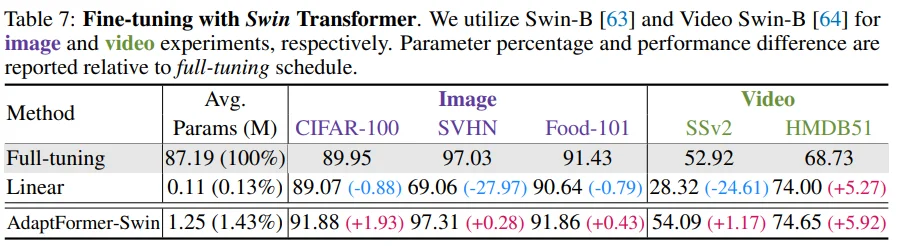
Table 7: VPT는 적용하기 어려운 swin transformer에서도 확장성이 좋은 AdaptFormer의 성능 향상을 확인할 수 있습니다.
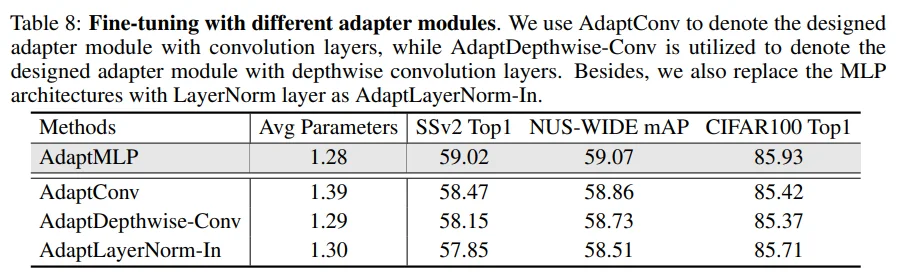
Table 8: MLP가 아닌 다른 Adapter module보다 AdaptMLP의 성능이 좋았습니다.
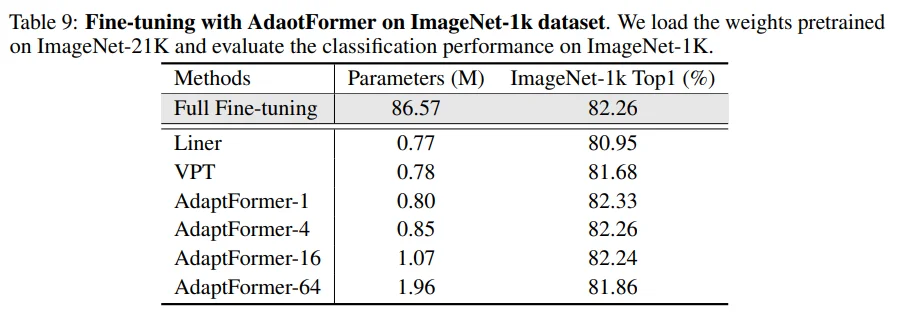
Table 9: ImageNet-21k로 pre-train한 이후에, ImageNet-1k로 fine-tune한 성능입니다. AdaprFormer의 mid dimension이 커짐에 따라 성능이 떨어지는 것을 확인할 수 있는데, 저자들이 말하길 ImageNet-1k가 ImageNet-21k의 subset이기 때문에 mid dimension 1로도 충분히 학습 가능한 것이고 그보다 커지게 되면 오버피팅되는 것이라고 설명합니다.