[논문리뷰] Barlow Twins: Self-Supervised Learning via Redundancy Reduction (ICML ‘21 Spotlight)
Introduction 부분은 굉장히 설명이 잘 되어 있어서 한번 읽어보시길 추천드려요.
Abstract
Contrastive objective에 기반하는 self-supervised learning(SSL)으로 학습할 경우, representation을 잘 추출하지 못하는 collapse 현상이 생기게 됩니다. (관련해서는 DirectCLR 논문을 참고하셔도 좋을 것 같습니다.)
이러한 collapsing 방지를 위해 이전 연구들에서 학습 안정성을 높이는 다양한 trick을 적용했습니다.
- SimCLR: negative sample도 학습하기 때문에 large batch 필요
- MoCo: asymmetric network design + momentum encoder
- DeepCluster, SeLa, SwAV: asymmetric network design (k-means, Sinkhorn-Knopp, prototype 등의 방법으로 loss의 target 할당)
- BYOL: asymmetric network design + momentum encoder
- SimSiam: asymmetric network design + stop-gradient
이와 다르게 Barlow Twins에서는 redundancy reduction 개념을 적용한 objective를 통해 collapsing을 극복할 수 있다고 주장합니다.
- large batch 필요 X
- predictor network와 같은 비대칭성 필요 X
- stop gradient 필요 X
- momentum encoder 필요 X
즉, contrastive SSL 학습 안정성을 높이기 위해 적용했던 여러 trick 없이도 collapsing 현상을 막을 수 있는 것입니다.
Method
먼저 Barlow Twins라는 논문 이름 중, Barlow는 redundancy reduction 이론을 제안했던 저자의 이름을 따왔고, 두 개의 동일한 (비대칭이 아닌) 네트워크를 사용한다는 점에서 Twins라는 이름을 붙인 것 같습니다.
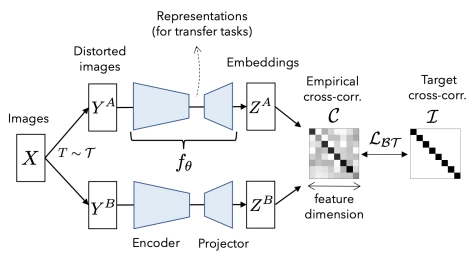
Figure 1에는 Barlow Twins의 framework를 표현했습니다. 눈여겨 볼만한 점은 network 2개의 구조가 동일하다는 것과, identity matrix를 target으로 embedding 간 cross-correlation matrix를 optimize하는 것입니다.
Barlow Twin’s objective
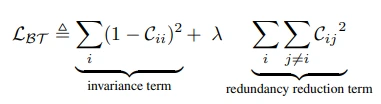
- invariance term: cross-correlation의 대각 행렬을 1로
- redundancy reduction term: cross-correlation의 대각 행렬이 아닌 값을 0으로
- 그리고 2개의 term이 lambda ($\lambda$) 라는 매개변수로 조절이 가능한 구조입니다.
즉, Barlow Twins는 embedding feature가 다른 feature와 중복이 되지 않도록 학습하는 것입니다.
참고로, contrasive SSL에서는 cosine similarity 계산 과정에서 feature를 축으로 L2-norm을 적용하지만, Barlow Twins에서는 batch를 축으로 normalization을 한다는 차이점이 있습니다.
Information theory
또한, Barlow Twin’s objective는 information theory 관점에서 Information Bottleneck objective와 유사하다고 주장합니다.
IB objective를 정말 간단하게 말씀드리면, 딥러닝 모델은 input data로부터 fitting phase와 compression phase를 거치면서 generalization 특성을 갖는다는 내용입니다. 이를 아래의 식으로 표현하기도 하는 것 같습니다. 참고로 I는 mutual information으로 MI라고도 표현하며 하나의 변수가 다른 변수에 제공하는 정보의 양을 의미합니다.
- minimize I(input, latent) + maximize I(latent, target)
위 식은 간단히 말하면, input으로부터 추출한 latent가 input과의 정보는 최소화하면서 (= generalization), latent가 target을 예측하는 정보를 충분히 보유하고 있다는 내용입니다.
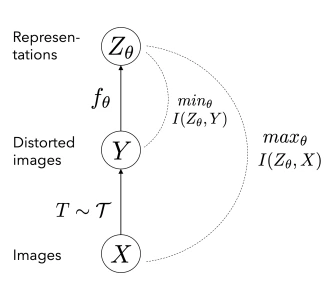
이러한 IB objective를 contrastive SSL에 접목하면, 위 그림처럼 표현할 수 있다고 주장합니다.
SSL에서 사용하는 augmentation을 일종의 distortion이라고 본다면, SSL은 distorted 이미지보다는 원본 이미지의 특성들을 잘 표현하는 representation을 뽑아낼 수 있도록 학습하는 과정이라고 볼 수 있다는 것이죠. (각기 다른 distorted (ex. crop) 이미지 2개로부터 얻은 representation 사이의 similarity를 높이도록 학습하는 과정을 생각해보시면 될 것 같습니다.)
- minimize I(distort, latent) + maximize I(image, latent)
여기서 더 궁금하신 분은 Information Bottleneck Theory 논문이나 Barlow Twins 논문의 Appendix를 참고하시면 좋을 것 같습니다.
Results
Barlow Twins의 성능이 SOTA보다 낮긴 하지만, 새로운 objective를 제안하였다는 점을 고려하면 준수한 성능 같습니다.
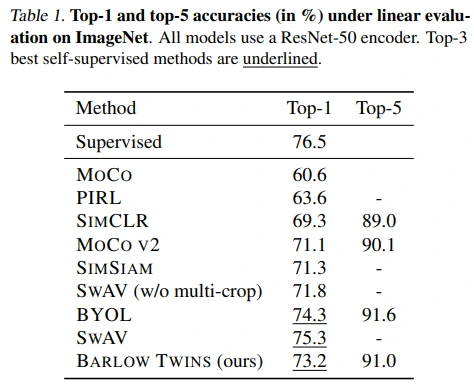
Table 1: linear probing 성능
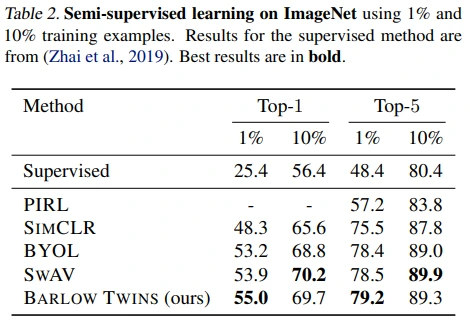
Table 2: semi-supervised learning 방식으로 fine-tune
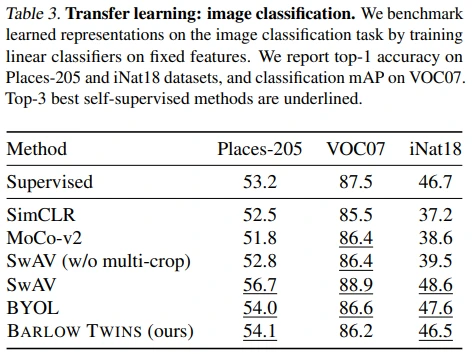
Table 3: 다른 이미지 분류 dataset으로 fine-tune (transfer learning)
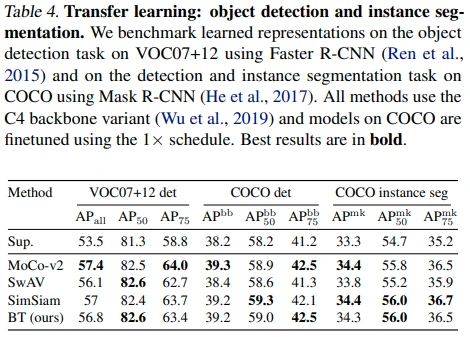
Table 4: 다른 task로 fine-tune (transfer learning)
Ablations
Loss function
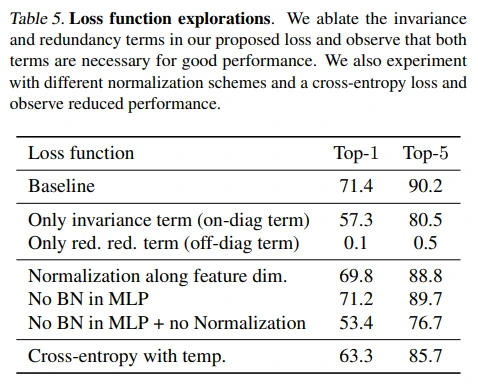
Barlow Twins objective term은 둘 다 있는 것이 좋다는 결과를 확인할 수 있습니다.
다음으로는 일반적인 contrastive SSL과 동일하게 feature를 축으로 normalization할 경우에는 (= embedding vector를 unit sphere 상에 mapping하는 느낌), 약간의 성능 하락이 있었습니다. (개인적으로는 각각의 feature에 존재하는 중복을 제거한다는 BT의 아이디어가 feature를 축으로 normalization 하는 것과 잘 맞지 않다고 생각되었습니다. 상호 간섭이 가능한 느낌..?)
이외에도 feature에 위와 같은 norm을 아예 하지 않거나, projector network에서 batch norm을 제거하는 방식도 성능이 하락하였습니다.
마지막으로 SimCLR의 NT-Xent (= cross-entropy) loss 구조를 가져와서 cosine similarity 대신 cross-correlation 값을 measure할때에도 성능이 하락하였습니다.
Robustness to batch size
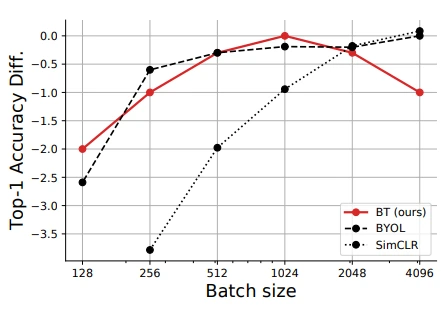
Contrasstive loss를 사용하는 SimCLR 대비 small batch size 성능이 robust합니다.
MSE loss를 사용하는 BYOL과 비교해서는 상대적으로 적은 batch size에서 성능이 좋은 것을 볼 수 있고, 오히려 batch가 커지면 성능이 떨어지는 모습도 확인해볼 수 있네요.
Effect of removing augmentations
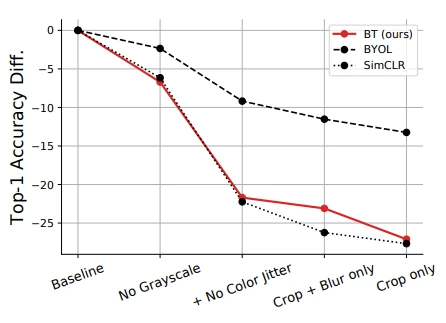
앞서 information theory로의 확장이나 augmentation 제거 실험을 보면, BT에서 augmentation의 역할이 중요한 것을 알 수 있습니다.
Projector network depth & width
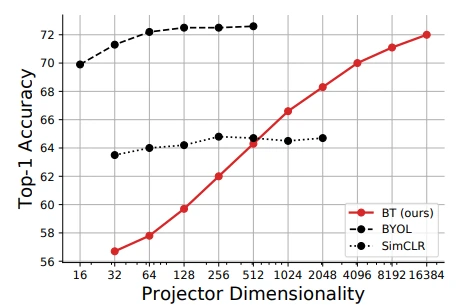
Projector의 dimension이 커질수록 BT의 성능도 증가하는 것을 볼 수 있습니다. BT의 objective를 생각해보면 feature가 많을수록 SSL 학습이 더 잘 될 수도 있겠다는 생각도 들고, dimension이 너무 커서 학습 시간이 오래 걸릴 수도 있겠다는 생각도 들었습니다. Epoch도 1000이니 말이죠.
Breaking symmetry

BT를 asymmetric 하게 바꾸었을 때의 성능 변화입니다.
BYOL with a larger projector/predictor/embedding
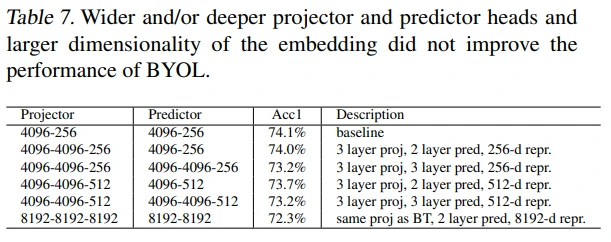
BT의 저자들이 얻은 인사이트를 바탕으로, BYOL의 projector와 predictor design을 바꾸어 봤는데 성능 개선은 없었다고 합니다.
Sensitivity to lambda
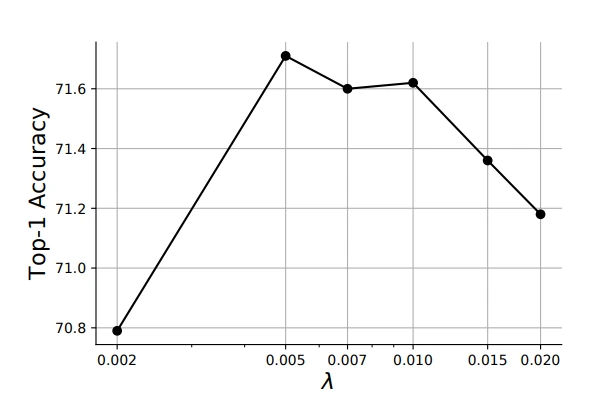
Objective에 사용되는 lambda의 영향은 크지 않은 것을 볼 수 있습니다.
Discussion
infoNCE
그렇다면 contrastive 학습에 자주 사용되는 infoNCE objective와는 어떤 유사점, 차이점이 있을까요?

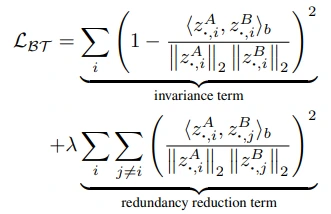
순서대로 infoNCE, Barlow Twins objective이고 비교를 위해 비슷한 형태로 표현하였습니다. 이들의 첫 번째 term은 distortion에 invariant한 embedding을 추출할 수 있도록 (유사도가 높아지도록) 학습하는 것을 목표로 하고 있습니다. 두 번째 term의 목표는 variability를 높이는 것으로 동일하지만 그 방식에서 차이가 존재합니다. InfoNCE는 pairwise distance를 멀어지게 함으로써, BT는 embedding component 각각의 decorrelation을 통해서 목표를 이루고자 합니다.
이러한 차이를 수학적으로 접근하면 infoNCE의 contrastive term은 non-parametric entropy estimator이기 때문에 차원의 저주에 빠지기 쉽고, low-dimension에서 estimation이 가능하며, large sample 수가 필요하다고 합니다. 반면, Barlow Twins의 redundancy reduction term은 proxy entropy estimator under Gaussian parametrization 이기 때문에 더 적은 sample이나, large-dimension 에서도 estimation이 가능하다고 하네요.
이외에도, infoNCE는 feature dimension, Barlow Twins는 batch dimension을 따라 normalization을 수행하고,
Barlow Twins에 존재하는 trade-off parameter lambda를 통해 term 간 가중치 조절이 가능하며, (IB framework 에서 min과 max 사이의 가중치 조절의 의미가 되기도 함)
InfoNCE에 존재하는 temperature parameter를 통해 batch 내에서 hard negative sample의 중요도를 조절합니다. (참고로 temperature는 수학적으로 non-parametric kernel density estimation 과정에서 kernel의 width를 조절하는 parameter로 볼 수 있다고 하네요.)
더 궁금하신 분은 Discussion의 infoNCE 부분과 Appendix를 참고하시면 도움될 것 같습니다.
Whitening
비슷한 시기에 나왔던 W-MSE 논문과 비교하면, Barlow Twins는 일종의 soft-whitening 기법으로 해석할 수 있다고 언급하고 있습니다. (성능은 BT가 더 좋다고 하네요.)
IMAX
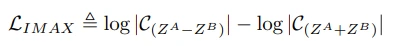
SSL의 초기 방법 중 하나인 information maximization 분야와 유사한 점이 있다고 언급합니다. 하지만 위 수식을 보면 embedding vector 2개에 대한 덧셈, 뺄셈 연산을 거친 vector의 covariance을 measure하는 IMAX objective는 직접적으로 정보량에 대한 연산을 수행한다는 점에서 차이가 있다고 밝히고 있으며, 실제로 ImageNet에 적용해보았을 때에도 학습이 정상적으로 되진 않았다고 주장합니다.
여기서 리뷰는 마무리하겠습니다.