[논문리뷰] LiT: Zero-Shot Transfer with Locked-image text Tuning (CVPR ‘22)
Abstract
Locked-image Tuning (LiT) 제안 = Contrastive-tuning
Pre-trained weight가 freeze된 image model에서 뽑아낸 image feature와 유사도가 높은 text feature를 뽑아내도록 text model을 학습시킨다.
New vision task에 대한 zero-shot transfer 성능을 기대할 수 있다.
1. Introduction
CLIP, ALIGN 모델은 language supervision과의 contrastive pre-training을 통해 new vision task에 대한 fine-tuning이 필요하지 않은 zero-shot transfer 성능을 기대할 수 있음을 보였습니다. (Ex. 이미지 분류의 경우, pre-training에서 image와 text의 align을 맞춰주면, inference에서 class name과의 score를 계산하여 class 예측 가능) 이를 보고 저자들은 CLIP, ALIGN이 사용했던 contrastive learning을 적용하면 image representation이 text representation과 유사해지는 점을 문제로 지적하였습니다.
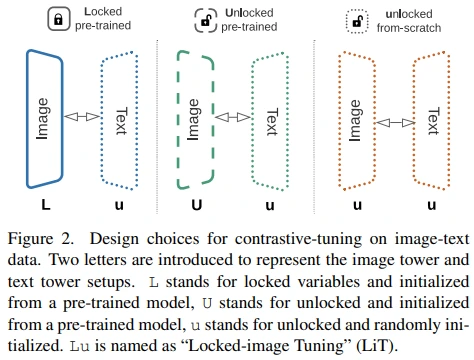
이를 해결하고자 image model과 text model의 초기 weight를 어떻게 조합해야 좋은지를 연구했고, 첫 번째 케이스인 image model은 lock(freeze)하고 text model은 scratch부터 학습하는 것이 가장 뛰어난 성능을 보인다고 밝혔습니다. 나아가, 저자들은 LiT의 성공이 vision-language alignment 과정에서 image model을 배제하였기 때문에 가능했다고 주장합니다. 즉, CLIP, ALIGN은 vision-language alignment를 맞추는 과정에서 image model의 성능이 희생된다는 것입니다.
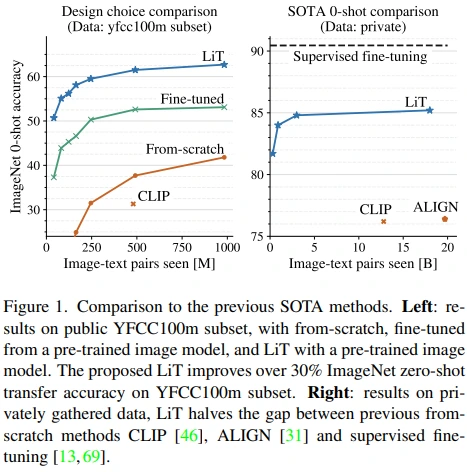
실제로 저자들이 했던 실험을 보면 학습하는 동안 CLIP, ALIGN보다 월등히 좋은 성능을 보이고 있습니다.
성능면에서는 Pretrained ViT-g/14를 LiT 방식으로 학습시켜 supervised fine-tuning 성능과의 격차를 50% 정도 줄였고, 몇몇 OOD dataset에서 SOTA를 기록하였습니다. 또한 ViT, ResNet, MLP-Mixer 등 다양한 아키텍쳐뿐만 아니라, DINO, MoCo-v3 등 self-supervised pretrained model에서도 성능이 검증되었습니다.
마지막으로 위 과정에서 다양한 모델들의 pre-trained weight로 실험하며, public dataset인 YFCC100M, CC12M을 사용했다는 점에서 zero-shot transfer 분야의 연구 발전에 contribution이 있다고 주장합니다.
2. Related work
LiT 논문의 근간인 trasnfer learning은 pre-train, fine-tune 2-step 학습을 통해 new task에 대한 학습을 (scratch보다) 빠르고 잘 하도록 하는 분야입니다. 그런데 BiT, ViT 등의 연구에서 model size, dataset size가 점점 커지면서 transfer 성능도 좋아지고 robustness도 향상되어, few-shot(zero-shot) learning에서도 충분한 성능을 보이게 되었습니다. 하지만 아쉬운 점은 여전히 2-step fine-tuning이라는 사실입니다.
이를 해결하고자 fine-tuning을 없앤 (지금에서야) zero-shot transfer라고 불리는 분야의 연구들도 존재했지만 2-step fine-tuning에 비해 그리 좋지 못한 성능을 보여주었습니다. 그런데 image-text alignment를 수행하는 CLIP, ALIGN 연구를 통해, contrastive learning과 large dataset을 기반으로 pre-train하면 zero-shot transfer 성능도 확보할 수 있음이 밝혀졌습니다. (CLIP, ALIGN이 large dataset을 구축할 수 있었던 이유는 image-text contrastive objective 덕분에 가능했습니다.)
3. Methods
3.1. Contrastive pre-training
Contrastive pre-training의 핵심은 image model과 text model이 유사한 representation을 뽑아내도록 학습된다는 것입니다. 이러한 objective를 통해 image-text alignment가 가능하다고 볼 수 있겠죠.
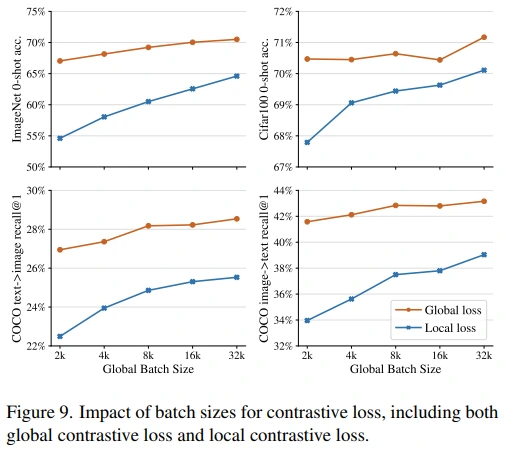
그리고 LiT에서는 각 device의 loss를 accumulate한 global contrastive loss를 사용함으로써, effective batch size와 hard negative를 늘려 robust하게 성능 향상이 가능했습니다. (Figure 9, Appendix F 참고)
3.2. Contrastive-tuning
저자들은 contrastive-tuning이 pre-training과 contrastive pre-traing의 장점은 가져온 방법이라고 주장합니다. 자세히 설명하면 pre-training은 dataset quality는 좋지만 학습했던 class에 종속된다는 단점이 있고, contrastive pre-training은 dataset quality는 떨어지지만 free-form text로부터 학습할 수 있다는 장점이 있습니다. 즉, contrastive-tuning이란, 좋은 quality의 dataset으로 학습된 pretrained weight로 image feature를 뽑아내면서, contrastive pre-training의 free-form text를 학습할 수 있다는 내용입니다. (당연한 내용이지만 논리적이고 설득력 good)
3.3. Design choices and Locked-image Tuning
Pretrained Image model과 Text model의 representation size가 다른 경우를 대비하기 위해, 각 model에 linear head를 추가하였다고 합니다.
Design 과정에서는 크게 다음의 2가지 사항을 고려하였으며 partial freeze, custom learning rate 등은 고려하지 않았다고 합니다.
Scratch vs Pre-trained
Lock(freeze) vs Fine-tuning
L = Pre-trained + Lock
U = Pre-trained + Fine-tuning
u = Scratch + Fine-tuning
4. Image-text datasets
CC12M (Conceptual Captions)
- latest version (12M 중 10M 사용)
YFCC100m (Yahoo Flickr Creative Commons)
- YFCC100m-CLIP (99.2M 중 15M 사용) (Appendix E 참고)
Our dataset
- ALIGN과 같은 방식으로, soft text filter를 사용하여 구축 (4B 중 3.6B 사용)
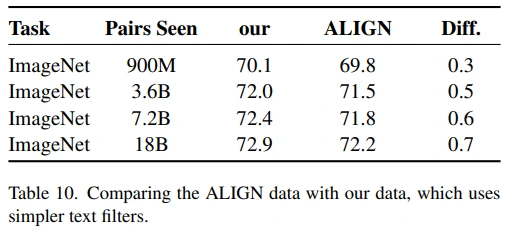
ALIGN에서는 hard text filter를 사용하여 4B 중 1.8B를 사용했다고 합니다. 그런데 table 10을 보면 LiT과 ALIGN의 dataset을 각각 학습했더니 soft text filter로 구축한 LiT dataset에서 성능이 더 좋았습니다.
(뇌피셜) ALIGN이 dataset 구축에 hard text filter를 사용했다는 점에서 caption quality를 중요하게 여겼다고 볼 수 있는데, image-text pair로 학습하는 contrastive learning 특성 상 중요했을 것으로 추측됩니다. 다른 관점에서는 LiT이 text model을 scratch부터 학습하기 때문에 quality에 상관없이 많은 text sample을 학습하는 것이 유리했을 수 있습니다.
5. Experiments
- 0-shot : zero-shot ImageNet classification
- T2I & I2T : MSCOCO retrieval
5.1. Comparison to the previous state-of-the-art
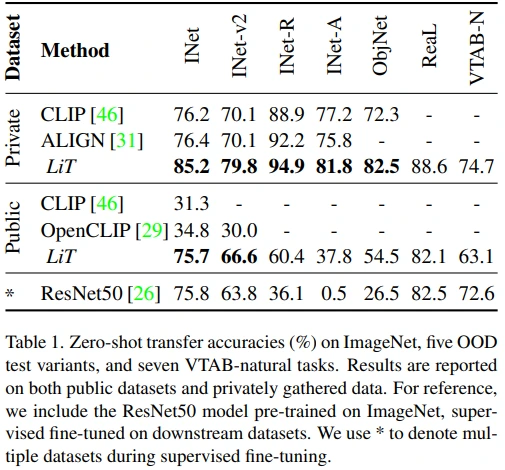
LiT 이외의 성능은 모두 각 논문에 기록된 값을 그대로 가져온 것으로 보입니다.
그리고 Private은 각 논문에서 수집했던 custom dataset을 의미하고, Public은 각 논문에서 사용했던 public dataset으로 학습된 성능을 기재한 것으로 파악됩니다. (참고로 Public LiT는 ImageNet-21k pretrained ViT-L/16 모델로 YFCC100m-CLIP과 CC12M dataset을 학습했습니다.)
언뜻 보시면 Private LiT 성능이 매우 좋구나 싶으실텐데, 아래와 같이 모델 사이즈가 동일하지 않은 것으로 파악됩니다.
- CLIP : ViT-L/14 (307M)
- ALIGN : EfficientNet-L2 (480M)
- LiT : ViT-g/14 pretrained on JFT-3B (1011M)
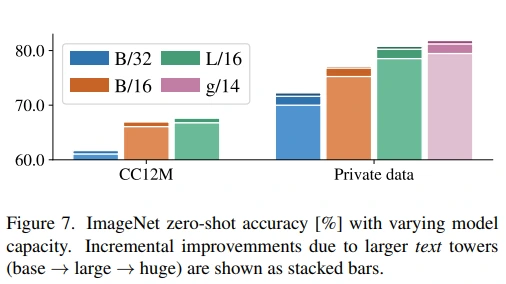
그래도 Appendix B의 각 모델 사이즈별 성능을 기록한 figure 7을 보면, L/16과 g/14 성능 차이가 크진 않아 보여서 LiT 방식이 기존보다 잘 된다는 사실은 변함없는 것 같습니다. (각 bar에 존재하는 눈금이 text model size별 성능을 의미합니다.)
또한, LiT는 ImageNet뿐만 아니라, OOD dataset, VTAB-natural task에서 zero-shot transfer SOTA 성능을 보였습니다.
Appendix I.2. VTAB Evaluation
VTAB-natural task로 zero-shot transfer 성능을 평가하려면, 이를 위한 새로운 prompt가 필요합니다. 그래서 CLIP에서 ImageNet에 사용했던 6개의 prompt 외에도 “CLASS”, “A photo of a CLASS” 등을 후보군으로 정한 다음, 각 dataset별로 optimize하는 과정을 거쳤다고 합니다. (Table 11, Table 12 참고)
재밌는 점은 VTAB에 3개의 category가 있는데, natural 성능에 비해 specialized, structured 성능이 매우 낮다는 것입니다. 특히, 3D depth estimation, counting 등의 task가 포함된 structured는 random guess와 별 차이가 없는 것으로 보이며, 이를 future work로 제안하고 있습니다. (Figure 13 참고)
5.2. Evaluation of design choices
Small-scale thorough investigation
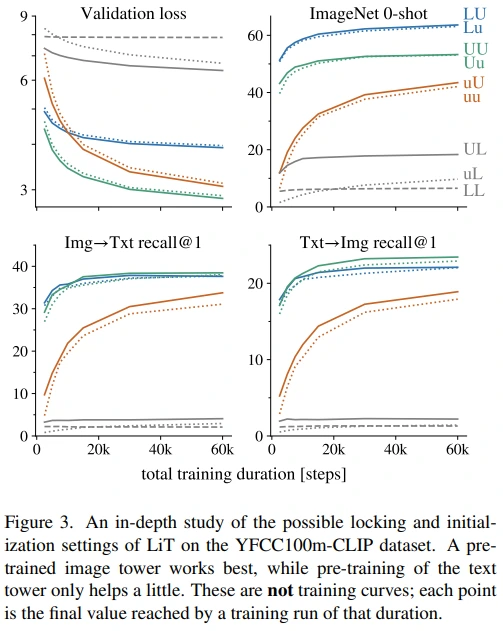
Image model과 text model의 initialization setting 실험입니다. (on YFCC100m-CLIP)
- LU, Lu (Blue) : Image model이 lock되는 것이 zero-shot 성능 면에서 좋습니다.
- UU, Uu (Green) : I2T, T2I retrieval 성능이 blue보다 근소하게 높습니다.
- UL, uL (Gray) : 반면, text model이 lock하면 학습이 잘 되지 않게 됩니다.
This still holds in the near-infinite data regime
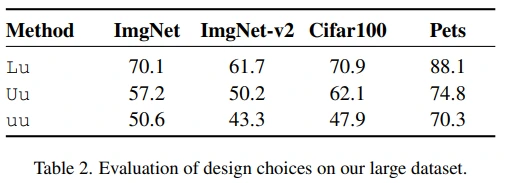
위 결과가 15M밖에 되지 않는 YFCC100m-CLIP dataset을 학습했기 때문이라고 생각할 수 있는데, 4B custom dataset으로 학습한 Table 2를 통해 dataset size에 상관없이 contrasive-tuning이 좋은 방법임을 알 수 있습니다.
저자들은 contrastive-tuning이 단순히 strong image embedder로부터 지식을 추출하도록 text model을 학습시킬 뿐이라는 지적도 물론 가능하다고 언급했지만, 어쨌든 LiT가 좋은 zero-shot 성능을 보인 점이 중요하다고 주장합니다.
Why is locked better than unlocked?
모델이 학습하면 더 좋은 성능을 보이는 것이 어쩌면 당연하기 때문에, 이러한 결과들은 직관적으로 이해되기 어려울 수 있다고 판단하여 추가 실험을 진행합니다.
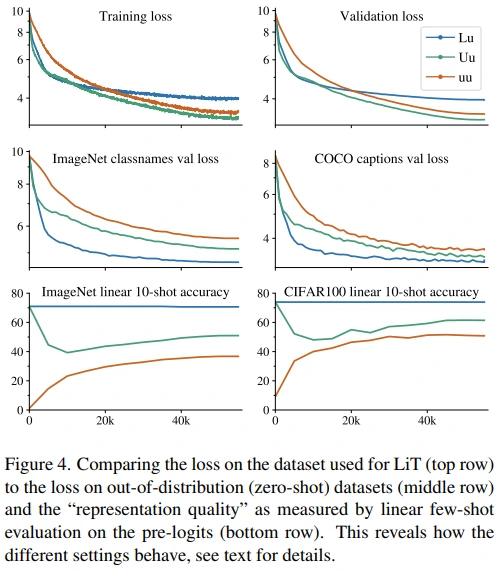
- 1행: train loss와 valid loss를 보면, Lu(blue)의 loss가 상대적으로 높은 것을 확인할 수 있습니다. (Image model이 lock되기 때문에 loss value가 상대적으로 높은 것이 큰 문제는 아닐 것으로 추측됩니다.)
- 2행: 일부 OOD dataset에서는 Lu loss가 잘 떨어지는 모습도 보이고 있습니다. (비록 1행에서 확인한 것처럼 loss value 자체는 높지만 image-text align은 잘 되고 있다는 증거로도 볼 수 있을 것 같습니다.)
- 3행: 결정적으로 few-shot evaluation을 통해 image model이 lock되지 않으면 성능이 점점 떨어지는 것을 확인 할 수 있습니다. (Lu는 lock되어 있기 때문에 성능이 유지되는 것이 당연함)
이를 근거로 저자들은 image model을 contrastively fine-tuning하는 것이 visual representation의 성능에 악영향을 미친다고 주장합니다.
추가적으로 lock 이후 unlock하거나, learning rate를 바꿔보는 실험은 Appendix H에서 확인할 수 있습니다. (유의미한 성능 향상은 없었다고 하네요.)
5.3. LiT works better for more generally pre-trained models
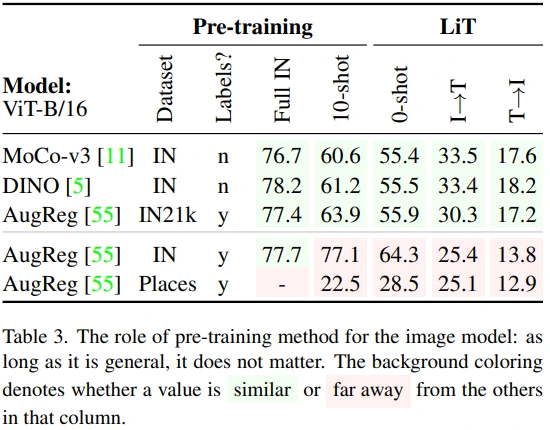
Image model의 pretrained weight에 대한 실험으로, 종합하면 general한 방식으로 broad한 dataset으로 학습된 weight가 좋은 성능을 보였습니다. (참고로, column 내에서 양상이 다른 경우에 빨간색 배경이 칠해졌습니다.)
Self-supervised learning
MoCo-v3, DINO를 통해 self-supervised learning weight에서도 LiT 방식이 잘 학습되는 것을 확인할 수 있습니다. 또한, AurReg IN21k에 비해 retrieval 성능이 더 좋은 것을 보면, self-supervised learning이 supervised learning보다 image-text align이 더 잘된다고 볼 수도 있습니다.
Dataset
AugReg만 고려하면 전반적으로 IN21k > IN > Places 순으로 성능이 좋다고 볼 수 있습니다. (물론 IN의 10-shot, 0-shot 성능이 IN21k보다 높지만 pre-train과 evaluation dataset이 같다는 점을 고려해야 하고, retrieval 성능까지 고려하면 IN21k가 더 높다고 볼 수 있습니다.)
또한, 저자들은 Places가 IN과 비교하여 데이터 수는 많지만 narrow dataset 이라서 성능이 낮다고 주장합니다. (그런데 IN이 아니라 다른 broad한 dataset과 비교하는게 더 적합하지 않나 싶습니다.)
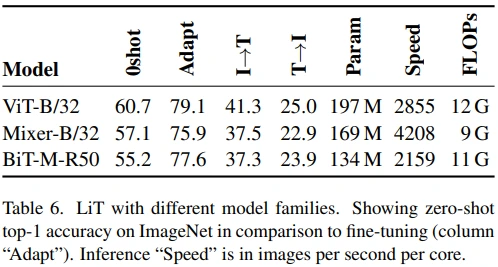
Appendix A를 참고하면 Mixer, BiT 구조에서도 LiT 방식이 잘 동작하는 것을 볼 수 있습니다.
5.4. Which text model to use?
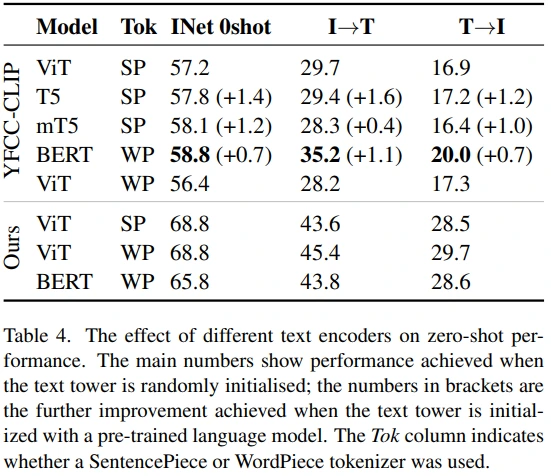
먼저 어떤 아키텍쳐가 더 좋은지를 실험했습니다. (이미지 모델은 AugReg-ViT-B/32, 데이터는 YFCC100M-CLIP)
초기 실험에서는 BERT 모델의 retrieval 성능이 특히 좋았습니다. (Random init weight는 main number, pretrained weight는 괄호 안) 이러한 성능이 WP tokenizer에 의한 것인지 파악하기 위해, ViT에 WP tokenizer로 학습시켜봤지만 유의미한 성능 향상은 볼 수 없었습니다.
그 다음으로 LiT 저자들이 구축한 large dataset으로 학습하였더니, BERT 보다도 ViT에서 더 좋은 성능을 기록하였습니다. 이를 두고 저자들은 초기 실험에서 BERT의 성능이 initialization 또는 LayerNorm에서 기인한 것으로 추측하고 있으며, BERT 모델의 학습 안정성이 떨어진다는 단점도 언급했습니다.
결론적으로 ViT 구조를 사용하기로 결정하였으며, WP tokenizer의 성능이 더 좋긴 하지만 학습 안정성을 고려하여 SP tokenizer를 사용했다고 합니다. (Appendix B에서 Text model의 size별 성능을 확인하실 수 있으며, 모델이 커질수록 더 좋은 성능을 기록했습니다.)
5.5. Do duplicate examples matter for LiT?
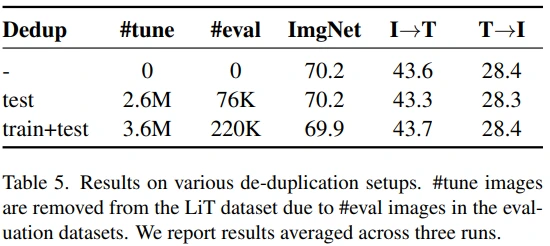
Web 상의 이미지를 수집하는 과정에서 upstream/downstream, train/test 사이에 의도치 않게 이미지가 중복되게 됩니다. 따라서 (CLIP, ALIGN과 마찬가지로) zero-shot transfer 성능이 단순히 데이터 중복에서 기인한 것은 아닌지 실험을 했고, 결론적으로 유의미한 성능차는 없었습니다. 이를 두고 저자들은 large upstream dataset으로 학습하면 중복 이미지를 memorize하지 못할 것이라고 추측했습니다. (추가로, Appendix K에서는 large model은 large dataset에서 memorize가 가능할 수 있다는 가설을 실험했는데요. 여기서도 유의미한 차이는 없었습니다.)
5.6. Technical advantages of locked image models
- Text model(tower)만 학습하기 때문에 효율적이며,
- Image augmentation이 없다면, image feature를 미리 계산하여 저장해두는 방식도 가능합니다.
5.7. Preliminary multilingual experiments
생략
6. Discussion
Limitations
Zero-shot transfer evaluation에 detection, segmentation, VQA, image captioning 등이 빠져있음
Cross-modal retrieval evaluation task에서 Lu 세팅이 타 세팅과 성능이 비슷함 (Classification만 좋은 성능) 즉, Lu 세팅에서 이미지 feature를 미리 저장해둠으로써 연산 cost를 줄일 수 있지만, 이러한 저장 비용이 과하게 요구되는 상황이면서 zero-shot classification이 관심사항이 아니라면 Uu 세팅도 괜찮을 것.
7. Conclusion
Zero-shot transfer task 성능 향상
Pre-trained image model을 사용하며, public dataset에 대한 성능을 기록함으로써 해당 분야의 연구를 public하게 접근할 수 있도록 하였음