[논문리뷰] VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning (ICLR ‘22)
Barlow twins 논문에 variance 개념을 추가한 VICReg 논문으로 joint embedding architecture, informational collapse와 같은 표현도 처음 사용한 것으로 알고 있습니다.
그리고 후속 논문인 VICRegL은 convnext with SSL을 최초로 다룬 논문으로 알고 있어서, 궁금하신 분은 찾아보셔도 좋을것 같습니다.
2. Intuition
VICReg은 다음의 3가지 개념을 loss에 녹였습니다.
- Invariance : two branch로부터 얻는 embedding vector 사이의 L2 distance
- Variance : (batch 내에서) embedding vector의 각 variable에서 일정 수준의 std를 margin으로 확보하기 위한 hinge loss
- Covariance : (batch 내에서) embedding vector의 variable 간 covariance를 0으로 (barlow twins의 decorrelation과 유사)
3. Related work
Contrastive learning
- Ex : InfoNCE, MoCo, SimCLR
- 단점 : large contrastive pair 필요 (high training cost)
Clustering methods
- Ex : DeepCluster, SwAV
- Cluster level에서 적용되는 contrastive learning으로 해석할 수 있다고 함 (contrastive learning은 image level)
- Cluster assignment 과정을 일종의 quantization 이라고도 설명함
- 단점 : 여전히 많은 양의 negative comparison 필요
Distillation methods
- Ex : BYOL, SimSiam, OBoW
- Knowledge distillation을 활용한 architectural trick으로 collapse 방지
- 단점 : collapsing 해결에 대해 명확히 설명하지 못한다고 주장함
Information maximization methods
- Ex : W-MSE, Barlow Twins
- Batch-wise norm을 활용한 embedding variable의 decorrelation으로 informational collapse 방지 (기존 SSL에서는 feature-wise norm을 사용하여 embedding variable 사이에 redundant information 문제가 야기된다고 주장함)
- VICReg에서는 variance term을 추가하여 embedding에 대한 normalization이 필요하지 않게 되었다고 주장함
4. Detailed description
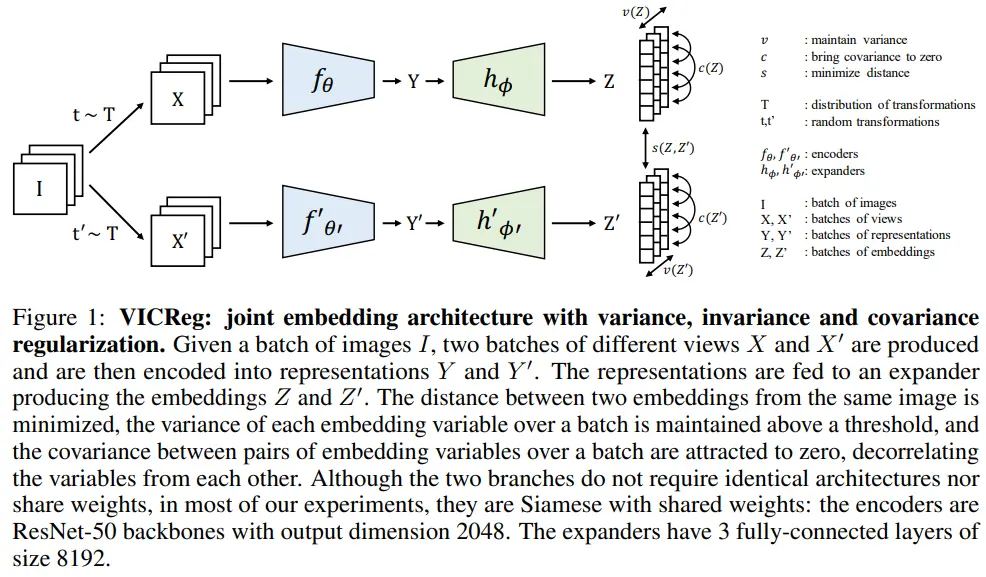
참고로 본 논문에서는 siamese net architecture + weight sharing 적용 (뒤에서 다루지만 꼭 필요한 것은 아님)
- Encoder(f) -> representation(Y) -> expander(h) -> embedding vector
- Expander
- 2개의 representation, Y와 Y’ 중에서 상이한 정보를 제거 (invariant representation 추출)
- representation의 dependency, correlation 감소
- Loss (on embedding)
- s : learn invariance to data trnsformation
- v : prevents norm collapse
- c : prevents informational collapsea
- Pre-train이 끝나면 encoder에서 얻는 representation으로 downstream task 학습
4.1 Method
먼저 variance term(v) 입니다.
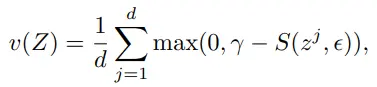
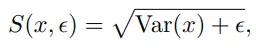
- max(0, *)는 relu로 구현
- gamma : constant target value for std (1 사용)
- epsilon : small scalar for numerical stabilities (1e-4 사용)
두번째로 covariance term(c)에서는 off-diagonal 계수가 낮아지도록 하여 decorrelation을 수행합니다.
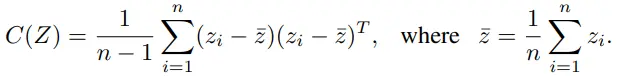
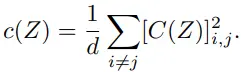
마지막 invariance(s)는 two branch에서 얻은 embedding 간 l2 distance를 가깝게 합니다.
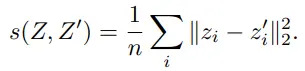
최종 loss 수식입니다.
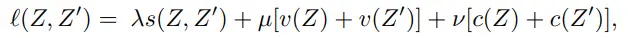
- covariance 계수는 1로 설정하고, grdi search 결과 lambda = mu > 1인 경우에서 성능이 좋았다고 합니다.
4.2 Implementation details
- loss coefficient
- invariance: lambda = 25
- variance: mu = 25
- covariance: v = 1
- encoder: ResNet-50
- expander
- linear(2048, 8192) + BN + ReLU
- linear(8192, 8192) + BN + ReLU
- linear(8192, 8192)
- optimizer: LARS
- epoch: 1000
- weight decay: 1e-6
- batch size: 2048
- lr = batch_size / 256 * base_lr = 2048 / 256 * 0.2 = 1.6
- cosine decay schdule
- warmup epoch: 10
- warmup end: 0.002
5. Results
5.1 Evaluation on ImageNet
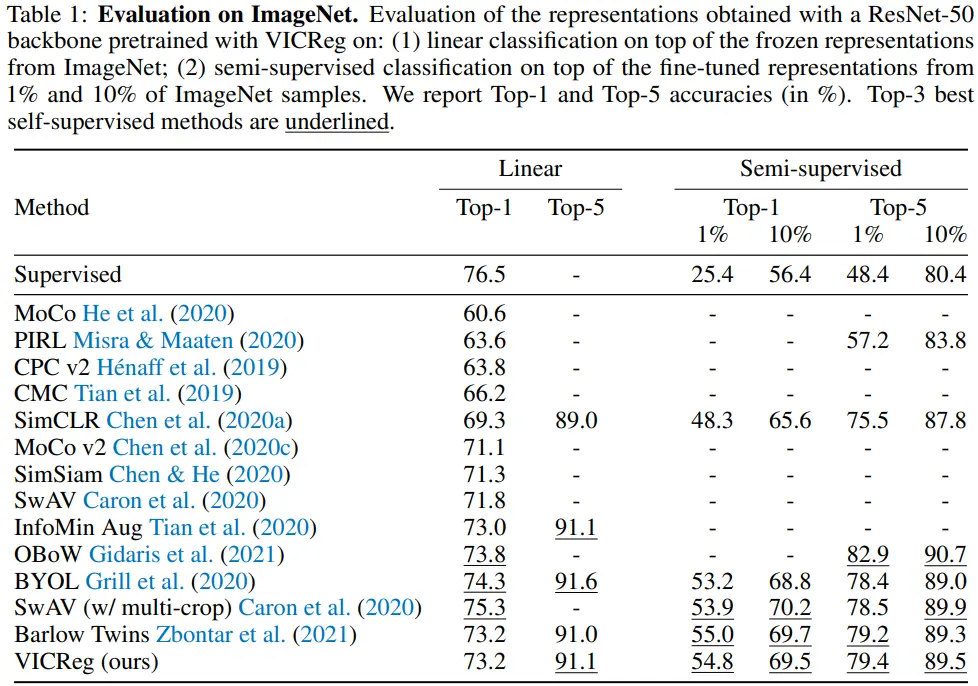
- 여러 번의 linear evaluation에서 성능 격차는 0.1%보다 적었다. (stable algorithm)
- Barlow twins 보다 explicit objective를 사용하면서, 성능은 비슷하다. (variance term)
5.2 Transfer to other downstream tasks
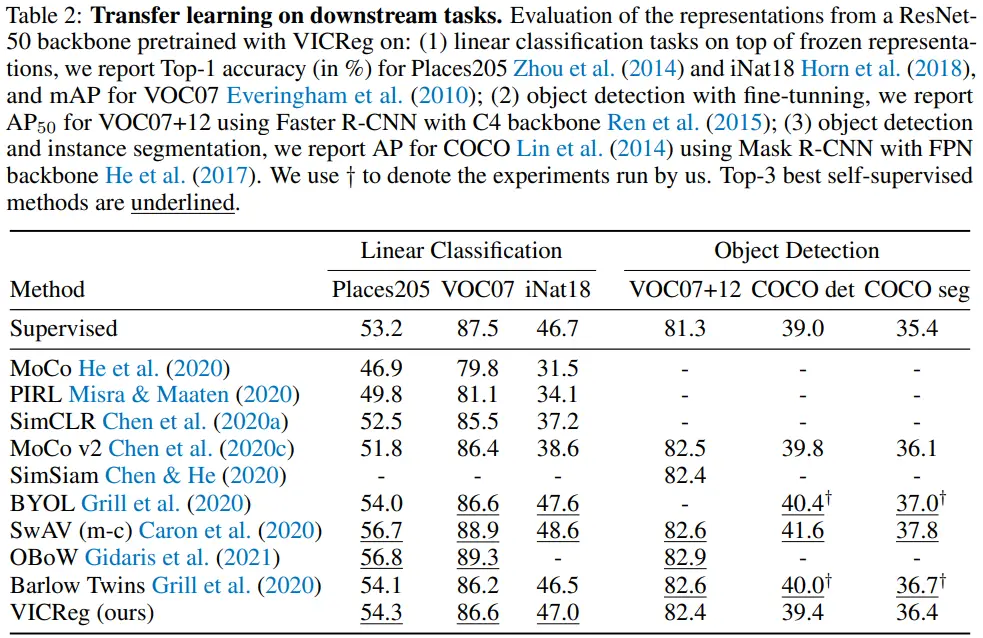
- Places205, VOC07, iNat18에서 준수한 성능을 보였으나, detection 성능은 부족하다.
5.3 Multi-modal pretraining on MS-COCO
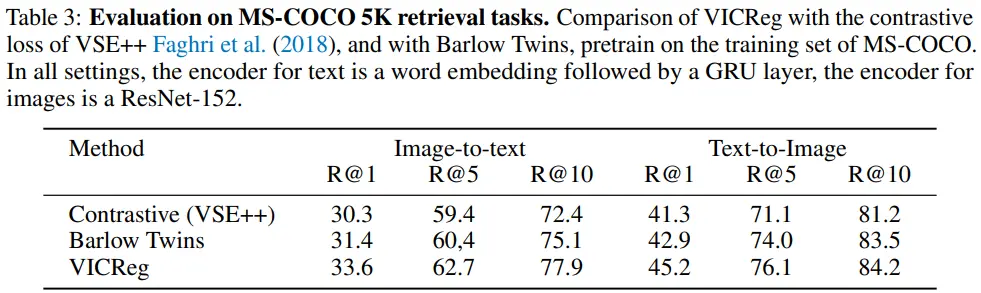
- VICReg과 Barlow twins의 또 다른 점은, VICReg의 경우 covariance term이 two branch 각각에 적용된다는 점이다.
- 이러한 VICReg의 특성을 통해 Barlow twins에 비해 image-text multi-modality 학습 성능이 좋은 것을 확인할 수 있다.
6. Analysis
Asymmetric networks
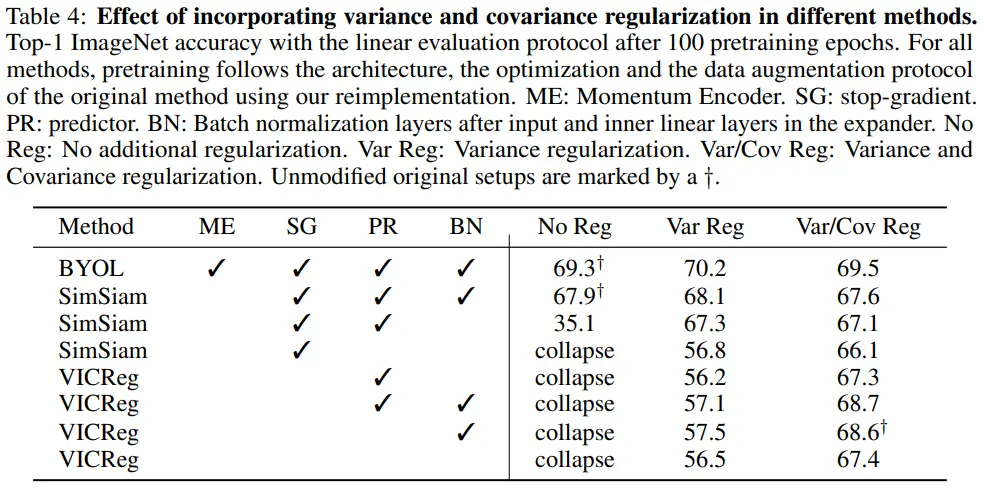
저자들은 architecture에 대한 ablation 실험을 진행한다. (100 epoch) Momentum encoder를 사용한 경우는 BYOL, stop-gradient operation을 사용한 경우에는 SimSiam의 protocol을 따른다.
- No Reg
- No Reg에서 collapse를 막으려면 SG와 PR이 반드시 필요함
- PR이 없으면 SG를 사용할 이유가 없음
- VR (No Reg -> Var Reg)
- VR + PR: 오히려 성능이 하락함 (즉, PR을 사용하는 의미가 없음)
- BYOL, SimSiam protocol에서 성능은 상승하였지만, 오히려 저자들은 very slow (informational) collapse가 발생하는 중이라고 주장함
- CR (Var Reg -> Var/Cov Reg)
- CR + PR: 성능이 상승하기도 함 (PR이 의미있어진다고 주장함)
- CR은 SG와 같이 동작하기 어렵다고 주장함
Weight sharing
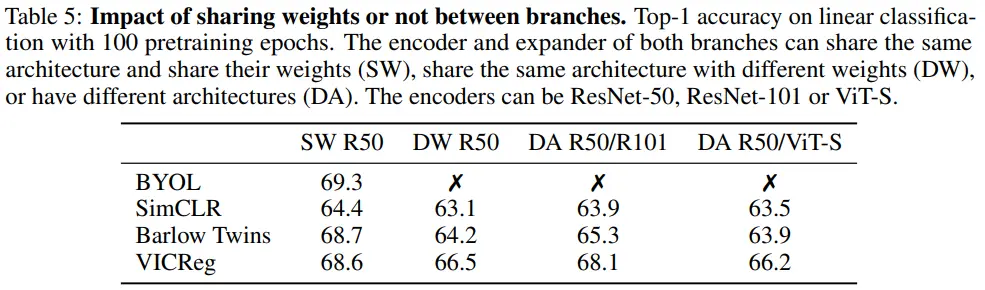
VICReg이 SimCLR보다 전체적으로 성능이 높고, Barlow twins보다 weight sharing, different architecture에 robust하다는 것을 확인할 수 있다.
7. Conclusion
종합하면 VICReg은 parameter, architecture, input modality에 robust한 특성을 가지게 되어 joint-embedding SSL의 확장성에 기여할 수 있다고 주장한다. (input modality에 robust할 수 있는 이유는 branch에 무관하게 regularization되기 때문)
Appendix
D.2 Pretraining and evaluation on ESC-50 audio classification
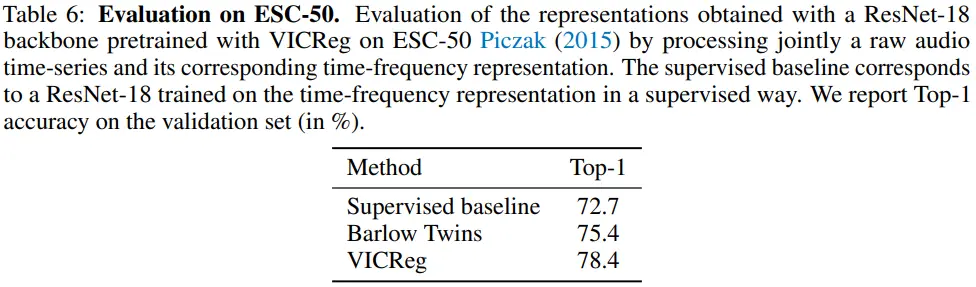
Raw audio time-series data를 input으로 audio classification task를 학습할 때에도, Barlow Twins 대비 VICReg 방식이 더 좋은 성능을 보이는 것을 확인할 수 있습니다. (단순히 Barlow Twins 대비 general input을 학습할 수 있다는 관점이며, 해당 task에서 SOTA를 경쟁하는 것은 아닙니다.)
D.5 Normalization
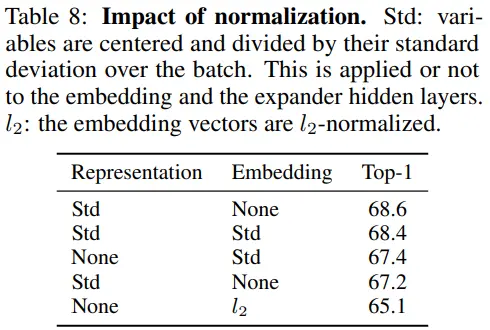
- Std / None : baseline
- Std / Std
- covariance matrix가 (-1, 1) 범위를 갖는 normalized auto-correlation matrix으로 바뀌게 되는데,
- 저자들이 생각하기에 covariance matrix 값이 다양해야 학습이 빨라진다고 함
- None / l2
- embedding에 l2 norm을 적용하고, variance term의 target을 1 대신 1/root(d)로 설정함으로써 unit sphere 상에 embedding이 mapping될 수 있도록 한 실험이다. 성능이 가장 낮다.
D.6 Expander network architecture

- Expander dimension이 커질수록 VICReg 성능이 향상된다.
D.8 Combination with BYOL and SimSiam
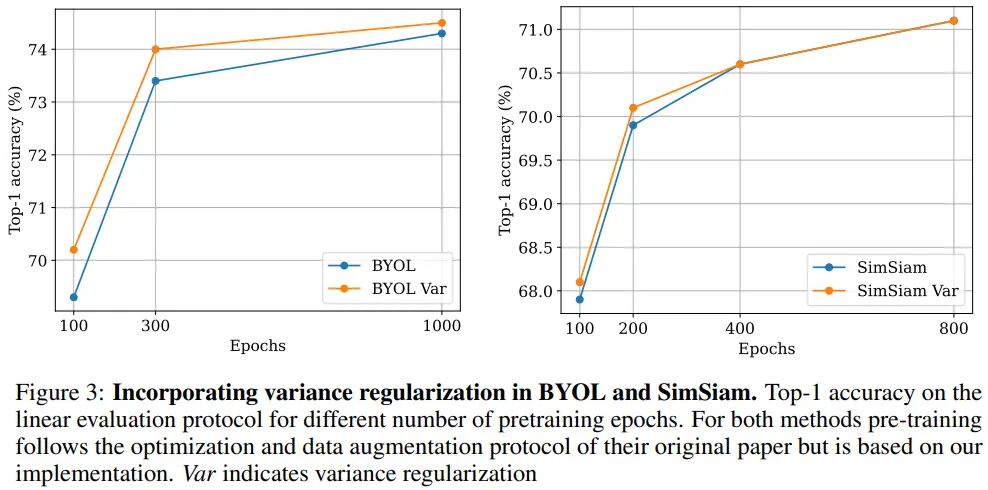
- Variance term이 BYOL과 SimSiam의 수렴 속도 향상에 기여한다.
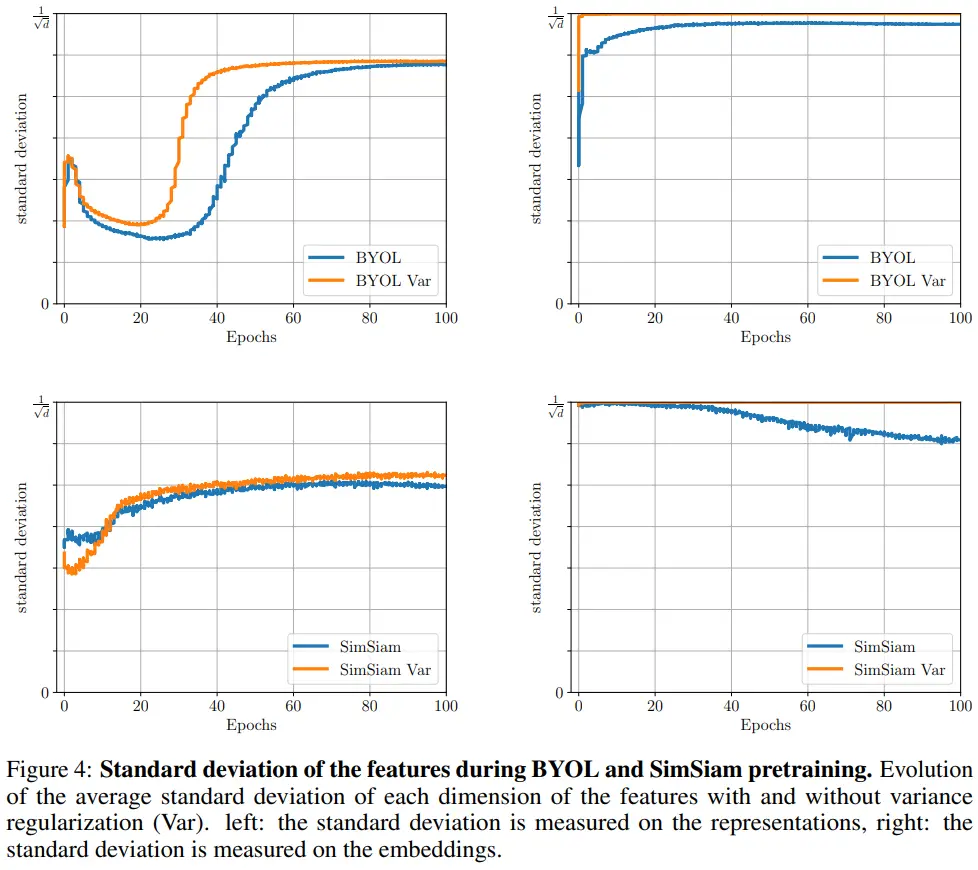
- left: std on represenetaion
- variance term으로 학습하는 경우 직접 loss가 적용되지 않음에도 std 향상에 기여한다.
- right: std on embedding
- embedding에 variance term이 적용되기 때문에, 1/root(d)에 수렴하는 것을 볼 수 있다.
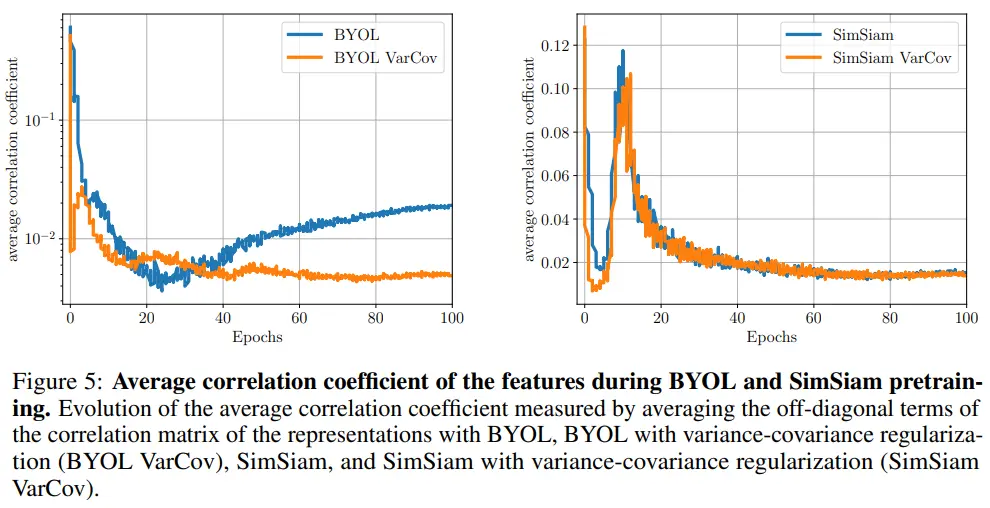
- Table 4를 참고하면 average correlation coefficient가 performance와 연관있음을 확인할 수 있다.
- BYOL : 실제 성능 향상 (69.3 -> 70.2)
- SimSiam : 실제 성능도 큰 변화 X (67.9 -> 68.1)