[논문리뷰] Vision Transformers Need Registers (‘23)
Abstract
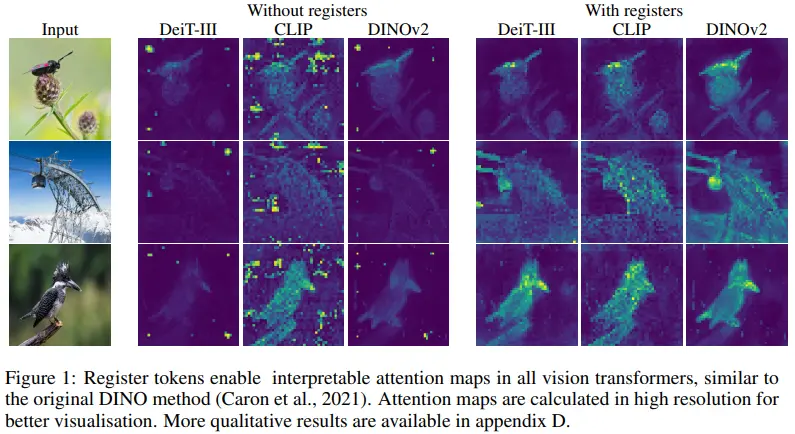
- Attention map에서의 artifact를 정의하여 그 원인을 규명하고, 이러한 현상을 해석할 수 있는 가설 제시
- Register token을 추가하여 ViT 아키텍쳐의 dense prediction task 성능 향상 (특히, DINOv2)
1. Introduction
대용량의 이미지를 pretrain한 모델로 downstream task를 해결하는 것은 당연한 접근이다. 특히, DINO의 경우 self-supervised로 학습함에도 downstream task에 대한 성능이 준수하고 unsupervised segmentation도 가능하기에 많은 관심을 받았다. 더 나아가, DINO의 attention map을 활용한 object dsicovery 알고리즘인 LOST도 등장하였다.
DINO 이후 제안된 DINOv2에서는 mono depth estimation, segmentation과 같은 dense prediction task에서 성능을 고도화했다. 그런데 DINOv2와 LOST가 incompatible한 것을 발견했고, DINOv2 attention map에 존재하는 artifact가 그 원인일 것으로 추정했다. 그리고 이후 supervised ViT(DeiT, OpenCLIP)에서도 동일한 artifact를 발견하게 된다. (Figure 2)
- DINO에서 artifact가 거의 존재하지 않는 이유는 2.2에서 추정하고 있다. (명쾌한 설명은 아님)

Artifacts를 나타내는 outlier들은 다음의 특징을 갖는 것을 파악했다.
- 약 10배 더 높은 norm을 가지며, 전체의 약 2%에 해당한다.
- 주로 middle layer에서 나타나며, 오래 학습하거나 모델이 큰 경우에 나타난다.
- discard local information
- 인근 patch와 유사도가 높아 original information(position, pixel)이 포함되지 않는다.
- contain global information
- 반면, patch에 classifier를 달아 예측하게 하면 일반적인 patch보다 outlier patch의 성능이 높더라.
- 이는 outlier patch가 이미지를 global하게 이해하고 있음을 의미한다.
즉, 모델이 알아서 유용하지 않은 patch를 찾아 spatial 정보를 버리고 global 정보가 담기도록 학습한다는 것이다. (ViT의 token 수가 제한되어 있기 때문에, 그 안에서 최대한 global 정보가 잘 담기게 학습된다고 설명한다.)
the model learns to recognize patches containing little useful information, and recycle the corresponding tokens to aggregate global image information while discarding spatial information
이를 해결하기 위해 register token을 추가했고, 그 결과
- outlier token이 사라지며,
- dense prediction task 성능이 향상되며,
- feature map이 smooth해진다.
- LOST를 활용한 object discovery 성능도 향상된다.
2. Problem Formulation
2.1 Artifacts in the Local Features of DINOv2
Artifacts are high-norm outlier tokens

- left: DINO와 DINOv2의 local feature norm을 시각화한 것으로, DINOv2에 존재하는 outlier가 high-norm인 것을 볼 수 있다.
- right: Small datasets에서 얻은 patch들의 분포를 나타내며, 임의로 지정한 cutoff value 150보다 높은 patch를 artifact로 정의한다. (모델에 따라 상이할 수 있음)
Outliers appear during the training of large models
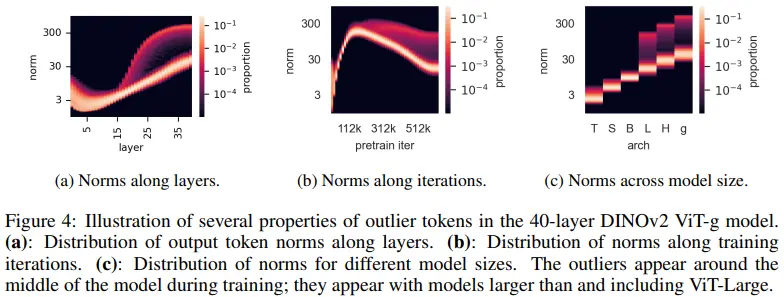
- a: 전체 40 layer 중 15번째 layer부터 발견된다.
- b: 전체 training의 약 1/3 지점에서부터 발견된다.
- c: Large, Huge, giant size에서 발견된다.
High-norm tokens appear where patch information is redundant
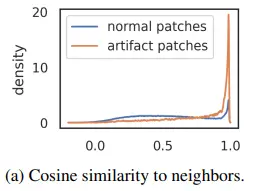
Artifact patch는 인접한 patch 4개와의 cosine 유사도가 높은 것을 보인다.
그렇다면 artifact patch는 어떤 정보를 갖고 있길래, 유사도가 높은 것일까?
High-norm tokens hold little local information
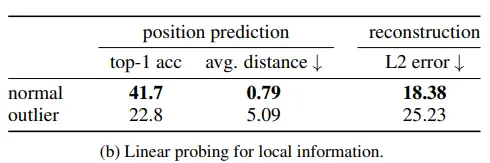
- Position prediction: 각 patch가 image 내에서 어디에 위치하는지를 예측 (positional embedding layer에서 position information이 주입되고, 이 정보가 얼마나 남아있는지를 예측)
- Pixel reconstruction
위 2개의 task에 대한 linear probing 성능이 낮기 때문에, local information이 artifact patch에 포함되어 있지 않다는 것을 알 수 있다.
Artifacts hold global information
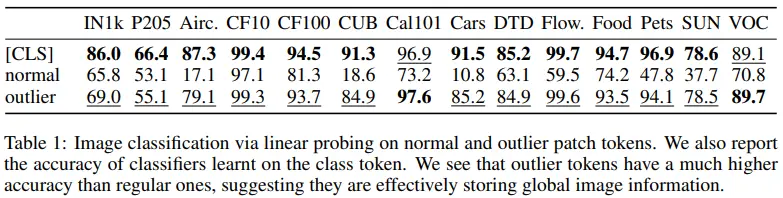
이번에는 image classification task에 대한 linear probing 성능이다. 여기서는 normal patch에 비해 outlier patch의 성능이 더 높다.
즉, outlier patch는 (normal patch에 비해) local information 보다 global information을 더 포함하고 있으며, 이로 인해 인접한 patch와의 cosine similarity가 높다고 볼 수 있다.
2.2 Hypothesis and Remediation
2.1 에서의 관측을 바탕으로 충분히 학습된 큰 사이즈의 모델은 중복되는 token이 global information을 처리할 수 있게 한다는 가설을 도출한다. 이러한 가설이 모델링 의도와는 일치하진 않지만 크게 문제되지는 않는다. 하지만 dense prediction task에서는 문제될 수 있다.
이를 해결하기 위해 register라는 additional token을 class token과 동일한 방식으로 추가한다. 그리고 register token은 inference에서 사용하지 않는다.
- 이러한 방식은 NLP 도메인의 Memory Transformer 논문에서 처음 적용되었다고 한다.
- 기존의 token들과 다른 점은 어떠한 정보도 주입되지 않고, token을 사용하지 않는다는 점이다.
물론 DINO에서는 왜 이러한 현상이 나타나지 않는지 규명하지 못 했다. 다만 DINO보다 모델 사이즈가 커지고, 학습 시간이 길어지면서 DINOv2에서 나타난 것으로 추정된다.
3. Experiments
3.1 Training Algorithms and Data
- DeiT3: supervised (ImageNet-22k, ViT-B)
- OpenCLIP: text-supervised (Open source, ViT-B/16)
- DINOv2: self-supervised (ImageNet-22k, ViT-L)
3.2 Evaluation of the Proposed Solution
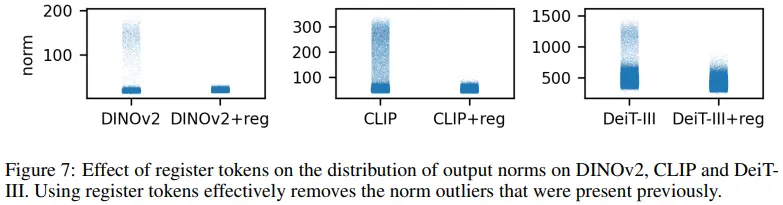
- Register token을 추가함으로써 patch norm이 크게 감소하는 것을 확인할 수 있다.
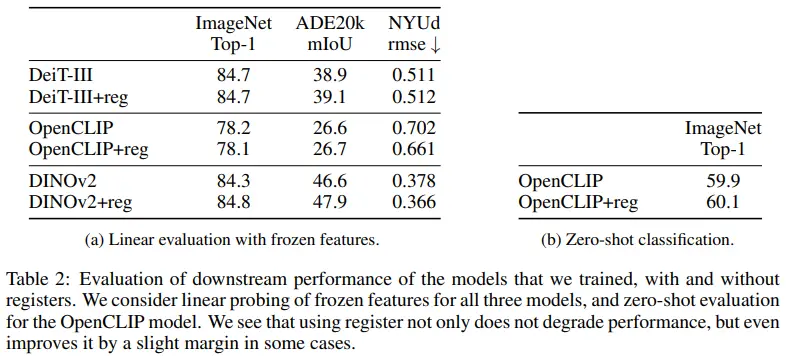
- Segmentation, depth estimation 성능을 보면 dense prediction 성능이 향상된다.
- ImageNet 성능도 유지되거나 상승했다. (특히, DINOv2에서 0.5%p 상승)

- Top: register가 없는 경우 artifact가 나타난다.
- Bottom: register가 하나만 추가되더라도 dense prediction task 성능이 크게 향상된다.
3.3 Object Dsicovery
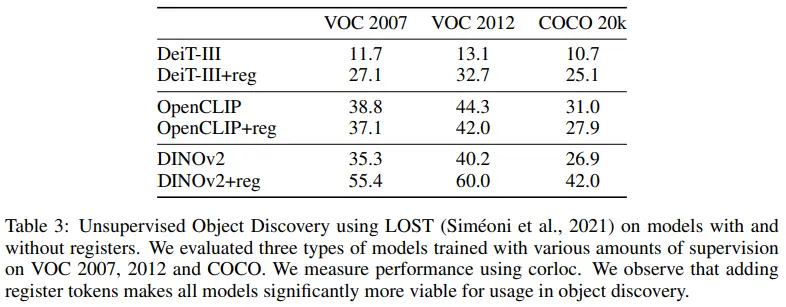
VOC 2007 dataset에 대한 DINO + LOST의 성능이 61.9인데, DINOv2 + reg + LOST의 성능이 이에 미치지는 못한다. 그럼에도 register를 사용함으로써 상당한 성능 개선을 이룰 수 있다.
3.4 Qualitative Evaluation of Registers

흥미로운 점은 각 reg 토큰들이 각기 다른 object에 attention되어 있다는 것으로, 저자들은 이에 대한 future work를 제안한다.
Appendix
A. Interpolation Artifacts and Outlier Position Distribution

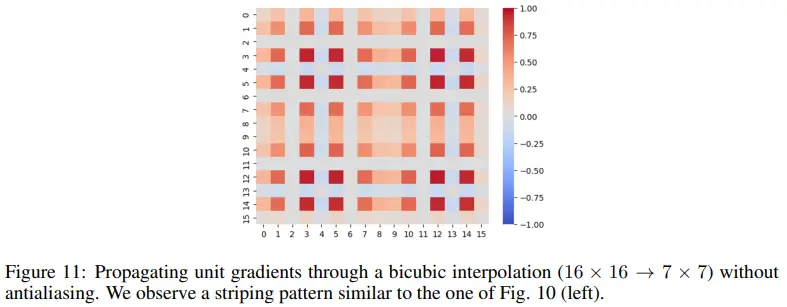
Official DINOv2에서는 positional embedding이 16x16에서 7x7로 interpolate될 때 antialiasing을 사용하지 않았다. 그래서 Figure 11과 같은 gradient pattern을 갖게 되어, Figure 10 좌측 그래프처럼 outlier token이 vertical-striped pattern을 갖고 나타나게 된다.
반면 저자들은 antialiasing을 적용하여 Figure 10의 우측 그래프처럼 vertical pattern을 없앨 수 있었다. 이때 중심부 보다는 가장자리에 outlier token이 많이 나타나는 것 또한, 대부분의 이미지가 object-centric하기에 가장자리 patch에 local information이 필요하지 않았을 것이라는 저자들의 가설을 뒷받침한다.